
Java查漏补缺
1. 基本数据类型范围
Java语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
1byte = 8bit (位)
| 类型名称 | 关键字(默认值) | 包装类 | 占用内存 | 取值范围 |
|---|---|---|---|---|
| 字节型 | byte(0) | Byte | 1 字节 | -128~127 |
| 短整型 | short(0) | Short | 2 字节 | -32768~32767 |
| 整型 | int(0) | Integer | 4 字节 | -2147483648~2147483647(21亿4千万) |
| 长整型 | long(0L) | Long | 8 字节 | -9223372036854775808L~9223372036854775807L |
| 单精度浮点型 | float(0.0f) | Float | 4 字节 | +/-3.4E+38F(6~7 个有效位) |
| 双精度浮点型 | double(0.0d) | Double | 8 字节 | +/-1.8E+308 (15 个有效位) |
| 字符型 | char('u0000') | Character | 2 字节 | ISO 单一字符集 |
| 布尔型 | boolean( false) | Boolean | 1 字节 | true 或 false |
2. 修饰符
| 修饰符 | 当前类 | 同包 | 子类 | 其他包 |
|---|---|---|---|---|
| public | YES | YES | YES | YES |
| protected | YES | YES | YES | NO |
| default | YES | YES | NO | NO |
| private | YES | NO | NO | NO |
- public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不 仅可以跨类访问,而且允许跨包(package)访问。
- protected: 介于public 和 private 之间的一种访问修饰符,一般称之为“保护形”。被其修饰的类、 属性以及方法只能被类本身的方法及子类访问,即使子类在不同的包中也可以访问。
- default:即不加任何访问修饰符,通常称为“默认访问模式“。该模式下,只允许在同一个包中进行访 问。
- private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的类、属性以 及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。
3. 转义字符
Java语言支持一些特殊的转义字符序列。
| 符号 | 字符含义 |
|---|---|
| \n | 换行 (0x0a) |
| \r | 回车 (0x0d) |
| \f | 换页符(0x0c) |
| \b | 退格 (0x08) |
| \0 | 空字符 (0x0) |
| \s | 空格 (0x20) |
| \t | 制表符 |
| " | 双引号 |
| ' | 单引号 |
| \ | 反斜杠 |
| \ddd | 八进制字符 (ddd) |
| \uxxxx | 16进制Unicode字符 (xxxx) |
4. 代码块
父类静态字段 -> 父类静态代码块 -> 子类静态字段 -> 子类静态代码块 -> 父类成员变量和非静态块(顺序加载) -> 父类构造函数 -> 子类成员变量和非静态块(顺序加载) -> 子类构造函数
- 就是被一对{}所括起来的代码
- 根据代码块定义的位置不同分为:局部代码块,构造代码块,静态代码块**
- 局部代码块:
- 在方法中出现;限定变量生命周期,及早释放,提高内存利用率
- 在同一个类中的同一个方法中,如果存在多个局部代码块,执行顺序是自上而下的。
public static void main(String[] args) {
//局部代码块
{
//在方法中出现
int num = 200;
System.out.println("局部代码块");
System.out.println(num); //输出200
}
//System.out.println(num); //出了代码块的范围,就不能再使用了!所以会报错!
}- 构造代码块 (初始化块):
- 在类中方法外出现;多个构造方法方法中相同的代码存放到一起,每创建一次对象就会执行一次,优先于构造函数执行。每次调用构造都执行,并且在构造方法前执行
- 无论类中有多少个构造代码块,构造代码块之间会先进行自上而下的顺序执行,然后再执行构造方法。
public class Student {
static int num;
//构造代码块
{
System.out.println("构造代码块");
//构造代码块,可以为该类的所有对象的成员变量赋值。
num = 100;
}
//构造方法
public Student() {
System.out.println("构造方法");
}
public static void main(String[] args) { //进程入口
}
}- 静态代码块:
- 在类中方法外出现,并加上static修饰;用于给类进行初始化,随着类加载而加载,一般用来给类进行初始化,在加载的时候就执行,并且只执行一次。
- 一般用于加载驱动,优先于主方法执行。
public class Student {
static {
System.out.println("静态代码块");
}
public static void main(String[] args) { //进程入口
}
}代码块执行顺序
public class Construct {
public static class Parent {
protected int i = 9;
protected int j = 0;
/* 静态初始化块 */
static {
System.out.println("父类--静态初始化块");
}
/* 初始化块 */
{
System.out.println("父类--初始化块");
}
/* 构造器 */
public Parent() {
System.out.println("父类--构造器"+"i=" + i + ", j=" + j);
j = 20;
}
}
public static class SubClass extends Parent {
/* 静态初始化块 */
static {
System.out.println("子类--静态初始化块");
}
/* 初始化块 */
{
System.out.println("子类--初始化块");
}
/* 构造器 */
public SubClass() {
System.out.println("子类--构造器"+" i=" + i + ",j=" + j);
}
}
/* 程序入口 */
public static void main(String[] args) {
System.out.println("子类main方法");
SubClass subClass = new SubClass();
}
}子类main方法
父类--静态初始化块
子类--静态初始化块
父类--初始化块
父类--构造器i=9, j=0
子类--初始化块
子类--构造器 i=9,j=205. 继承&实现
- 【继承】Java只支持单继承,不支持多继承。(一个儿子只能有一个爹);
- 【继承】Java支持多层继承(爹的上面可以有爷爷);
- 【实现】Java支持多实现(implement);
- 【继承】子类只能继承父类所有非私有的成员(成员方法和成员变量);
- 【继承】子类不能继承父类的构造方法,但是可以通过super关键字去访问父类构造方法;
- 【继承】抽象类 被继承体现的是:”is a”的关系。抽象类中定义的是该继承体系的共性功能。
- 【实现】接口 被实现体现的是:”like a”的关系。接口中定义的是该继承体系的扩展功能。
- 【继承】子类中所有的构造方法默认都会访问父类中空参数的构造方法,子类会继承父类中的数据,可能还会使用父类的数据。所以子类初始化之前,一定要先完成父类数据的初始化。
- 【继承】每一个构造方法的第一条语句默认都是:super() Object类最顶层的父类。
class Father {
public Father() {
super();//默认继承object类。
System.out.println("Father的构造方法");
}
}
class Son extends Father {
super(); //这是一条隐藏语句,用来访问父类中的空参构造。
public Son() {
System.out.println("Son的构造方法");
}- 【继承】父类没有无参构造方法,子类怎么办?super(…)或者this(….)必须出现在构造方法的第一条语句上
class Son extends Father {
public Son() {
//super("李四",24);//调父类
this("王五",25);//调本类,不能同时写
System.out.println("Son的空参构造");
}
public Son(String name,int age) {
super(name,age);
System.out.println("Son的有参构造");
}
}6. 重写和重载
- 方法重写:子类中出现了和父类中方法声明一模一样的方法。与返回值类型有关,返回值是一致(或者是子父类)的。
- 方法重载:本类中出现的方法名一样,参数列表不同的方法。与返回值类型无关。
7. final关键字
修饰类,类不能被继承
修饰变量,变量就变成了常量(量命名规范_所有字母大写),只能被赋值一次
修饰方法,方法不能被重写
修饰局部变量
- 基本类型,是值不能被改变
- 引用类型,是地址值不能被改变,对象中的属性可以改变
8. 抽象类
1. 特点
抽象类和抽象方法必须用abstract关键字修饰
- abstract class 类名 {}
- public abstract void eat();
抽象类不一定有抽象方法,有抽象方法的类一定是抽象类或者是接口
抽象类不能实例化那么,抽象类如何实例化呢?
- 按照多态的方式,由具体的子类实例化。其实这也是多态的一种,抽象类多态。
抽象类的子类,要么是抽象类,要么重写抽象类中的所有抽象方法
抽象类的成员特点
- 成员变量:既可以是变量,也可以是常量;abstract不能修饰成员变量。
- 构造方法:用于子类访问父类数据的初始化。
- 成员方法:既可以是抽象的,也可以是非抽象的。
抽象类的成员方法特性:
- 抽象方法 强制要求子类做的事情。
- 非抽象方法 子类继承的事情,提高代码复用性。
abstract不能和哪些关键字共存
- abstract和static
- 被abstract修饰的方法没有方法体
- 被static修饰的可以用类名.调用,但是类名.调用抽象方法是没有意义的
- abstract和final
- 被abstract修饰的方法强制子类重写
- 被final修饰的不让子类重写,所以他俩是矛盾的
- abstract和private
- 被abstract修饰是为了让子类看到并强制重写
- 被private修饰不让子类访问,所以他俩是矛盾的
2. 抽象类和普通类的区别和一些特性
- 抽象类不可以直接实例化,只可以用来继承
- 子类继承抽象类后,必须实现父类的所有抽象方法, 如果抽象类的派生子类没有实现其中的所有抽象方法,那么该派生子类仍然是抽象类, 只能用于继承,而不能实例化;
- 一个类里面定义了抽象方法,那么该类必须定义为抽象类,但是一个抽象类里面可以有抽象方法,也可以没有
- 构造方法和静态方法不可以修饰为abstract!!!(注意:static和abstract绝对不是互斥的,虽然两者不能同时修饰某个方法,但他们可以同时修饰内部类)
- 抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
9. 接口特点
接口用关键字interface表示:interface 接口名 {}
类实现接口用implements表示:class 类名 implements 接口名 {}
接口不能实例化,按照多态的方式来实例化。
接口的子类
- 可以是抽象类。但是意义不大。
- 可以是具体类。要重写接口中的所有抽象方法。(推荐方案)
接口成员特点
- 成员变量;只能是常量,并且是静态的并公共的。默认修饰符:public static final
- 构造方法:接口没有构造方法。
- 成员方法:默认修饰符:public abstract,只能是抽象方法。在jdk8中,还可以有静态方法和default方法。并且静态方法与default方法可以有方法体
10. 接口和抽象类的区别
10.1 定义与用途
- 抽象类:
- 抽象类是使用 abstract 关键字声明的类。
- 可以包含抽象方法(没有方法体的方法)和具体方法(有方法体的方法)。
- 抽象类主要用于表示一种“模板”或“基类”,子类继承它并实现其抽象方法。
- 接口:
- 接口是使用 interface 关键字声明的。
- 接口中的所有方法默认都是 public abstract 的(即使你不显式声明),但从 Java 8 开始,接口可以包含默认方法(default)和静态方法(static)。
- 接口主要用于定义一组行为规范,多个类可以通过实现接口来遵循这些规范。
2. 继承与实现
- 抽象类:
- 类只能继承一个抽象类(单继承)。
- 子类必须实现抽象类中的所有抽象方法,除非子类本身也是抽象类。
- 接口:
- 一个类可以实现多个接口(多重实现)。
- 实现接口的类必须实现接口中所有的抽象方法,除非该类本身是抽象类。
3. 构造函数
- 抽象类: 抽象类可以有构造函数,用于初始化成员变量或执行某些操作。
- 接口: 接口不能有构造函数,因为接口不能被实例化。
4. 字段
- 抽象类: 抽象类可以有实例变量、静态变量和常量(final 字段)。
- 接口: 接口中所有的字段默认都是 public static final 的,即常量。从 Java 9 开始,接口可以包含私有字段(但仍然需要是 static final)。
5. 方法
- 抽象类: 可以包含抽象方法和具体方法。 具体方法可以在抽象类中实现逻辑,供子类继承使用。
- 接口: 接口中的方法默认是 public abstract 的。 从 Java 8 开始,接口可以包含默认方法(default)和静态方法(static),允许提供一些默认实现。
6. 访问修饰符
- 抽象类: 抽象类和其方法可以使用任何访问修饰符(public, protected, private 或包级私有)。
- 接口: 接口中的方法默认是 public 的,无法使用其他访问修饰符。 接口中的字段默认是 public static final 的。
7. 实现复杂性
- 抽象类: 抽象类更适合用于具有共同属性和行为的类层次结构,尤其是当这些类共享某些实现时。
- 接口: 接口更适合用于定义行为规范,允许多个不相关的类实现相同的接口,从而实现多态性。
抽象类:
抽象类不可以实例化,只能够用来继承;
包含抽象方法的一定是抽象类,但是抽象类不一定含有抽象方法;
抽象类中的抽象方法的修饰符只能为public或者protected,默认为public;
一个子类继承一个抽象类,则子类必须实现父类抽象方法,否则子类也必须定义为抽象类;
抽象类可以包含属性、方法、构造方法,但是构造方法不能用于实例化,主要用途是被子类调用;
抽象类中可以包含非抽象的方法;
抽象类的引用可指向子类的实例;接口:
接口用interface关键修饰。接口中所有的方法为抽象方法 ,**注明:**jdk8之后提供了默认方法和静态方法(且这两种方法可以存在方法体)
接口可以包含变量、方法;变量被隐式指定为public static final,方法被隐式指定为public abstract(JDK1.8之前);
接口中的变量都为常量
接口不能实例化,只被实现,还能被接口继承
接口的实现类必须全部实现接口中的方法,如果不实现,可以将子类变成一个抽象类
接口支持多继承,即一个接口可以extends多个接口,间接的解决了Java中类的单继承问题;
一个类可以实现多个接口;
接口的引用指向实现类的实例
JDK1.8中对接口增加了新的特性:
- (1)、默认方法(default method):JDK 1.8允许给接口添加非抽象的方法实现,但必须使用default关键字修饰;定义了default的方法可以不被实现子类所实现,但只能被实现子类的对象调用;如果子类实现了多个接口,并且这些接口包含一样的默认方法,则子类必须重写默认方法;
- (2)、静态方法(static method):JDK 1.8中允许使用static关键字修饰一个方法,并提供实现,称为接口静态方法。接口静态方法只能通过接口调用(接口名.静态方法名)。
C:设计理念区别
- 抽象类 被继承体现的是:”is a”的关系。抽象类中定义的是该继承体系的共性功能。
- 接口 被实现体现的是:”like a”的关系。接口中定义的是该继承体系的扩展功能。
文字描述
1.接口比抽象类更加抽象,因为抽象类中可以定义构造器,可以有抽象方法和具体方法,而接口中不能定义构造器而且其中的方法全部都是抽象方法。
2.类可以实现很多个接口,但是只能继承一个抽象类。一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现, 否则该类仍然需要被声明为抽象类。
2.抽象类可以在不提供接口方法实现的情况下实现接口。Java 接口中声明的变量默认都是final的。抽象类可以包含非final的变量。Java 接口中的成员函数默认是 public 的。抽象类的成员函数可以是 private,protected 或者是 public。
3.接口是绝对抽象的,不可以被实例化。抽象类也不可以被实例化,但是,如果它包含 main方法的话是可以被调用的。(抽象类和接口都不能够实例化,但可以定义抽象类和接口类型的引用)接口可以继承接口。抽象类可以实现(implements)接口**,抽象类可继承具体类,但前提是具体类必须有明确的构造函数**。有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法。
4.接口可以继承接口,而且支持多重继承。抽象类可以实现(implements)接口,抽象类可继承具体类也可以继承抽象类。
11. ==号和equals方法的区别
==是一个比较运算符号,既可以比较基本数据类型,也可以比较引用数据类型,
- 基本数据类型比较的是值
- 引用数据类型比较的是地址值
equals方法是一个方法,只能比较引用数据类型,所有的对象都会继承Object类中的方法,如果没有重写Object类中的equals方法,equals方法和==号比较引用数据类型无区别,重写后的equals方法比较的是对象中的属性,String重写的equal方法
12. Integer类-128到127陷阱
public static void main(String[] args){
Integer a1 = 127 ;
Integer a2 = 127 ;
Integer b1 = 128 ;
Integer b2 = 128 ;
Integer c1 = 1000 ;
Integer c2 = 1000 ;
int d1= 127;
int d2 = 127;
int e1 = 128;
int e2 = 128;
int f1 = 1000;
int f2 = 1000;
System.out.println(a1 == a2); //true
System.out.println(b1 == b2); //false
System.out.println(c1 == c2); //false
System.out.println(d1 == d2); //true
System.out.println(e1 == e2); //true
System.out.println(f1 == f2); //true
}- 当数据为基本类型int的时候,运行的结果都是true,而如果是封装类型Integer的时候,数据为127的时候使true,128和1000都为false
- 首先我们要理解==比较的是什么,它比较的是栈中数据是否相同,我们都知道,基本类型的数据的变量名和值都存在栈中(作为类的属性的情况除外),因此,所有int类型的数据运行都会为true。
- Integer是引用类型,会把它的值存在堆中,栈中存储的是变量名及堆中数据的地址
- 自动拆箱与自动装箱:Integer a = 1;其实代表的是Integer a = new Integer(1);我们不需要去进行初始化,这个方法会自己初始化在堆中开辟一片区域存储数据。自动拆箱也类似int b = a;代表的是int b = Integer.valueOf(a);同样不需要我们主动调用方法。
- 出现false,因为每次初始化都会开辟新的区域,虽然两块区域可能储存的值相同,但是它们是堆中两块不同的区域,栈中存储的地址不同,因此比较会出现false。
- Integer 的值为-128~127 的时候就会认为是true是因为Java对-128127在常量池中进行了缓存(Java规定在-128127之间的Integer类型的变量,直接指向常量池中的缓存地址,不会new开辟出新的空间。 )
13. Java正则表达式
| 字符 | 说明 |
|---|---|
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如, n匹配字符 n。\n 匹配换行符。序列 \\ 匹配 \ ,\( 匹配 (。 |
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。 |
| * | 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。 |
| {n} | n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 |
| {n,} | n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。 |
| {n,m} | m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。 |
| . | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"("或者")"。 |
| (?:pattern) | 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。 |
| (?=pattern) | 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| (?!pattern) | 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配"Windows 3.1"中的 "Windows",但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| x|y | 匹配 x 或 y。例如,'z|food' 匹配"z"或"food"。'(z|f)ood' 匹配"zood"或"food"。 |
| [xyz] | 字符集。匹配包含的任一字符。例如,"[abc]"匹配"plain"中的"a"。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,"abc"匹配"plain"中"p","l","i","n"。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,"a-z"匹配任何不在"a"到"z"范围内的任何字符。 |
| \b | 匹配一个字边界,即字与空格间的位置。例如,"er\b"匹配"never"中的"er",但不匹配"verb"中的"er"。 |
| \B | 非字边界匹配。"er\B"匹配"verb"中的"er",但不匹配"never"中的"er"。 |
| \cx | 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。等效于 0-9。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与 \f\n\r\t\v 等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和 \cK 等效。 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。与"A-Za-z0-9_"等效。 |
| \xn | 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。 |
| \num | 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义码或反向引用。如果 n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
| \nm | 标识一个八进制转义码或反向引用。如果 nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
| \nml | 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
| \un | 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
Pattern和Matcher的使用
Pattern p = Pattern.compile("a*b");
Matcher m = p.matcher("aaaaab");
boolean b = m.matches();14. Math类/Random类/BigInteger类/BigDecimal类
(1)Math类方法使用
public static void main(String[] args) {
System.out.println(Math.PI);
System.out.println(Math.abs(-10)); //取绝对值
System.out.println(Math.ceil(12.01));//获取向上取整,但是结果是一个double值
System.out.println(Math.ceil(12.99));
System.out.println(Math.floor(12.01));//获取向下取整,但是结果也是一个double值
System.out.println(Math.floor(12.99));
System.out.println(Math.max(20, 30));//取最大值
System.out.println(Math.min(20, 30));//取最小值
System.out.println(Math.pow(2, 3)); //2.0的3次方
System.out.println(Math.random());//生成0.0到1.0之间的所有小数,包括0.0,不包括1.0
System.out.println(Math.round(12.3f));//四舍五入
System.out.println(Math.sqrt(2));//开平方
}(2)Random类方法使用
Random类的概述
- 此类用于产生随机数如果用相同的种子创建两个 Random 实例,
- 则对每个实例进行相同的方法调用序列,它们将生成并返回相同的数字序列。
构造方法
- public Random()
- public Random(long seed)
成员方法
- public int nextInt()
- public int nextInt(int n) 生产0 到n的随机数,不包括n;
(3)BigInteger类方法使用
BigInteger的概述
- 可以让超过Integer范围内的数据进行运算
构造方法
- public BigInteger(String val)
成员方法
- public BigInteger add(BigInteger val) //加
- public BigInteger subtract(BigInteger val) //减
- public BigInteger multiply(BigInteger val) //乘
- public BigInteger divide(BigInteger val) //除
- public BigInteger[] divideAndRemainder(BigInteger val) //返回一个包含divideToIntegralValue的结果,随后其余与上根据上下文设置进行舍入计算两个操作数的结果,结果由两个元素组成的BigDecimal数组。
(4)BigDecimal类方法使用
A:BigDecimal的概述
- 由于在运算的时候,float类型和double很容易丢失精度,演示案例。
- 所以,为了能精确的表示、计算浮点数,Java提供了BigDecimal
- 不可变的、任意精度的有符号十进制数。
B:构造方法
- public BigDecimal(String val)
C:成员方法
- public BigDecimal add(BigDecimal augend)
- public BigDecimal subtract(BigDecimal subtrahend)
- public BigDecimal multiply(BigDecimal multiplicand)
- public BigDecimal divide(BigDecimal divisor)
15.日期类的使用
(1)date类
//将时间字符串转换成日期对象
String str = "2000年08月08日 08:08:08";
SimpleDateFormat sdf = new SimpleDateFormat("y年M月d日 HH:mm:ss");
Date d = sdf.parse(str); //将时间字符串转换成日期对象 Ctrl+1抛出异常
System.out.println(d);
//将日期对象转换为字符串
Date d = new Date(); //获取当前时间对象
SimpleDateFormat sdf = new SimpleDateFormat("y年M月d日 HH:mm:ss"); //创建日期格式化类对象
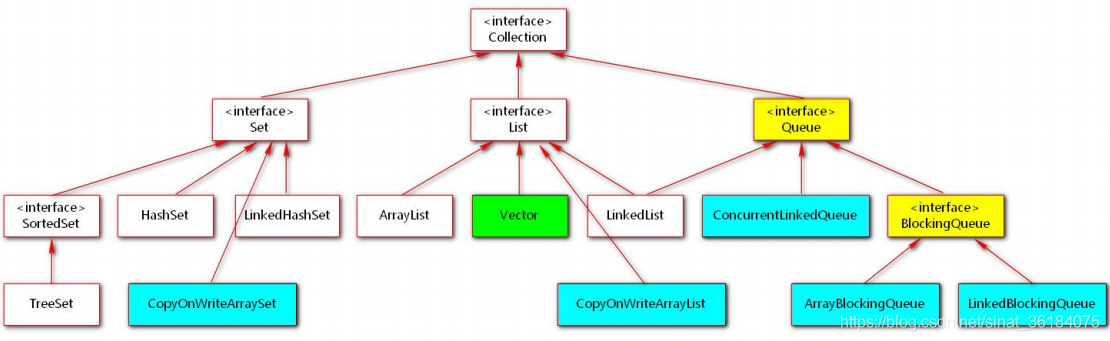
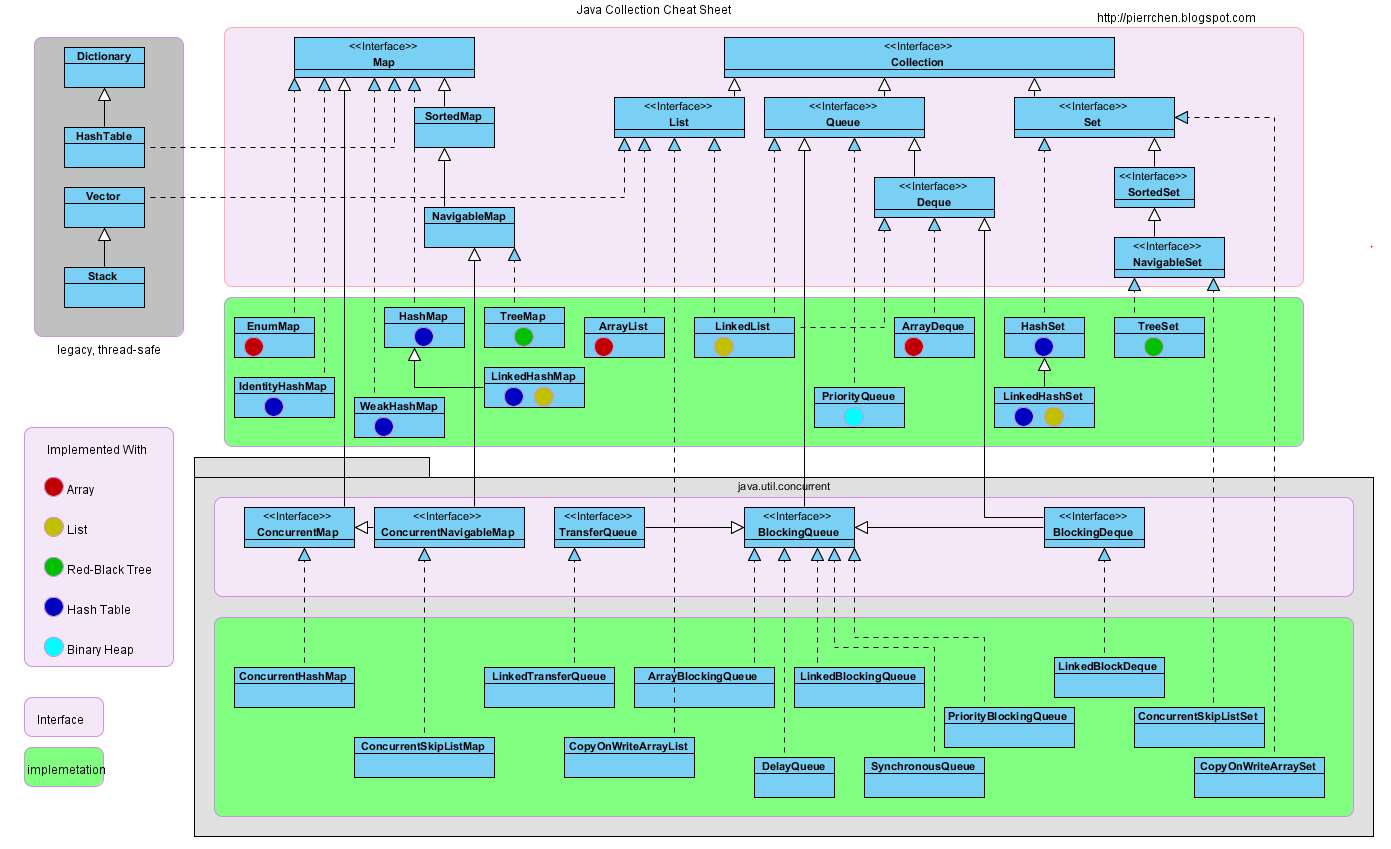
System.out.println(sdf.format(d));16. 集合体系
17. CopyOnWriteArrayList如何做到线程安全的
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。
由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制,如果有线程并发的读,则分几种情况:
1、如果写操作未完成,那么直接读取原数组的数据;
2、如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
3、如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
可见,CopyOnWriteArrayList的读操作是可以不用加锁的。
- CopyOnWriteArrayList的使用场景
通过上面的分析,CopyOnWriteArrayList 有几个缺点:
1、由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
2、不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
CopyOnWriteArrayList透露的思想
如上面的分析CopyOnWriteArrayList表达的一些思想:
1、读写分离,读和写分开
2、最终一致性
3、使用另外开辟空间的思路,来解决并发冲突
Collections.synchronizedList
CopyOnWriteArrayList和Collections.synchronizedList是实现线程安全的列表的两种方式。
两种实现方式分别针对不同情况有不同的性能表现,其中CopyOnWriteArrayList的写操作性能较差,而多线程的读操作性能较好。
而Collections.synchronizedList的写操作性能比CopyOnWriteArrayList在多线程操作的情况下要好很多,而读操作因为是采用了synchronized关键字的方式,其读操作性能并不如CopyOnWriteArrayList。因此在不同的应用场景下,应该选择不同的多线程安全实现类。
总结:写操作多用Collections.synchronizedList,读操作多用CopyOnWriteArrayList
18. 集合的线程安全性
线程安全的集合:
- ConcurrentHashMap
- Collections.synchronizedList
- CopyOnWriteArrayList
- CopyOnWriteArraySet
除此之外还有ConcurrentSkipListMap、ConcurrentSkipListSet、ConcurrentLinkedQueue、ConcurrentLinkedDeque等,至于为什么没有ConcurrentArrayList,原因是无法设计一个通用的而且可以规避ArrayList的并发瓶颈的线程安全的集合类,只能锁住整个list,这用Collections里的包装类就能办到。
(1)概念
- **线程安全:**就是当多线程访问时,采用了加锁的机制;即当一个线程访问该类的某个数据时,会对这个数据进行保护,其他线程不能对其访问,直到该线程读取完之后,其他线程才可以使用。防止出现数据不一致或者数据被污染的情况。
- **线程不安全:**就是不提供数据访问时的数据保护,多个线程能够同时操作某个数据,从而出现数据不一致或者数据污染的情况。
- 对于线程不安全的问题,一般会使用synchronized关键字加锁同步控制。
- 线程安全 工作原理: jvm中有一个main memory对象,每一个线程也有自己的working memory,一个线程对于一个变量variable进行操作的时候, 都需要在自己的working memory里创建一个copy,操作完之后再写入main memory。 当多个线程操作同一个变量variable,就可能出现不可预知的结果。 而用synchronized的关键是建立一个监控monitor,这个monitor可以是要修改的变量,也可以是其他自己认为合适的对象(方法),然后通过给这个monitor加锁来实现线程安全,每个线程在获得这个锁之后,要执行完加载load到working memory 到 use && 指派assign 到 存储store 再到 main memory的过程。才会释放它得到的锁。这样就实现了所谓的线程安全。
(2)线程的安全控制有三个级别
• JVM 级别。大多数现代处理器对并发对 某一硬件级别提供支持,通常以 compare-and-swap (CAS)指令形式。CAS 是一种低级别的、细粒度的技术,它允许多个线程更新一个内存位置,同时能够检测其他线程的冲突并进行恢复。它是许多高性能并发算法的基础。在 JDK 5.0 之前,Java 语言中用于协调线程之间的访问的惟一原语是同步,同步是更重量级和粗粒度的。公开 CAS 可以开发高度可伸缩的并发 Java 类。
• 低级实用程序类 -- 锁定和原子类。使用 CAS 作为并发原语,ReentrantLock 类提供与 synchronized 原语相同的锁定和内存语义,然而这样可以更好地控制锁定(如计时的锁定等待、锁定轮询和可中断的锁定等待)和提供更好的可伸缩性(竞争时的高性能)。大多数开发人员将不再直接使用 ReentrantLock 类,而是使用在 ReentrantLock 类上构建的高级类。
• 高级实用程序类。这些类实现并发构建块,每个计算机科学课本中都会讲述这些类 -- 信号、互斥、闩锁、屏障、交换程序、线程池和线程安全集合类等。大部分开发人员都可以在应用程序中用这些类,来替换许多同步、 wait() 和 notify() 的使用,从而提高性能、可读性和正确性。
(3)常见的线程安全操作列举几个
- 加锁同步synchronizedLock等
- wait() notify()线程调度 已实现执行的同步
- ThreadLocal局部变量 每一个线程都有一份数据
- Semaphore 信号量
- volatile 保证一个变量的线程安全
(4)相关集合对象比较
- **Vector、ArrayList、LinkedList:****1、Vector:**Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。 **2、ArrayList:**a. 当操作是在一列数据的后面添加数据而不是在前面或者中间,并需要随机地访问其中的元素时,使用ArrayList性能比较好。 b. ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。 **3、LinkedList:**a. 当对一列数据的前面或者中间执行添加或者删除操作时,并且按照顺序访问其中的元素时,要使用LinkedList。 b. LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
Vector和ArrayList在使用上非常相似,都可以用来表示一组数量可变的对象应用的集合,并且可以随机的访问其中的元素。
- **HashTable、HashMap、HashSet:**HashTable和HashMap采用的存储机制是一样的,不同的是: **1、HashMap:**a. 采用数组方式存储key-value构成的Entry对象,无容量限制; b. 基于key hash查找Entry对象存放到数组的位置,对于hash冲突采用链表的方式去解决; c. 在插入元素时,可能会扩大数组的容量,在扩大容量时须要重新计算hash,并复制对象到新的数组中; d. 是非线程安全的; e. 遍历使用的是Iterator迭代器;**2、HashTable:**a. 是线程安全的; b. 无论是key还是value都不允许有null值的存在;在HashTable中调用Put方法时,如果key为null,直接抛出NullPointerException异常; c. 遍历使用的是Enumeration列举;**3、HashSet:**a. 基于HashMap实现,无容量限制; b. 是非线程安全的; c. 不保证数据的有序;
- **TreeSet、TreeMap:**TreeSet和TreeMap都是完全基于Map来实现的,并且都不支持get(index)来获取指定位置的元素,需要遍历来获取。另外,TreeSet还提供了一些排序方面的支持,例如传入Comparator实现、descendingSet以及descendingIterator等。 **1、TreeSet:**a. 基于TreeMap实现的,支持排序; b. 是非线程安全的;**2、TreeMap:**a. 典型的基于红黑树的Map实现,因此它要求一定要有key比较的方法,要么传入Comparator比较器实现,要么key对象实现Comparator接口; b. 是非线程安全的;
- **StringBuffer和StringBulider:**StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串。
1、在执行速度方面的比较:StringBuilder > StringBuffer ; 2、他们都是字符串变量,是可改变的对象,每当我们用它们对字符串做操作时,实际上是在一个对象上操作的,不像String一样创建一些对象进行操作,所以速度快; 3、 StringBuilder:线程非安全的; 4、StringBuffer:线程安全的;
- **对于String、StringBuffer和StringBulider三者使用的总结:**1.如果要操作少量的数据用 = String 2.单线程操作字符串缓冲区 下操作大量数据 = StringBuilder 3.多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
19. 泛型
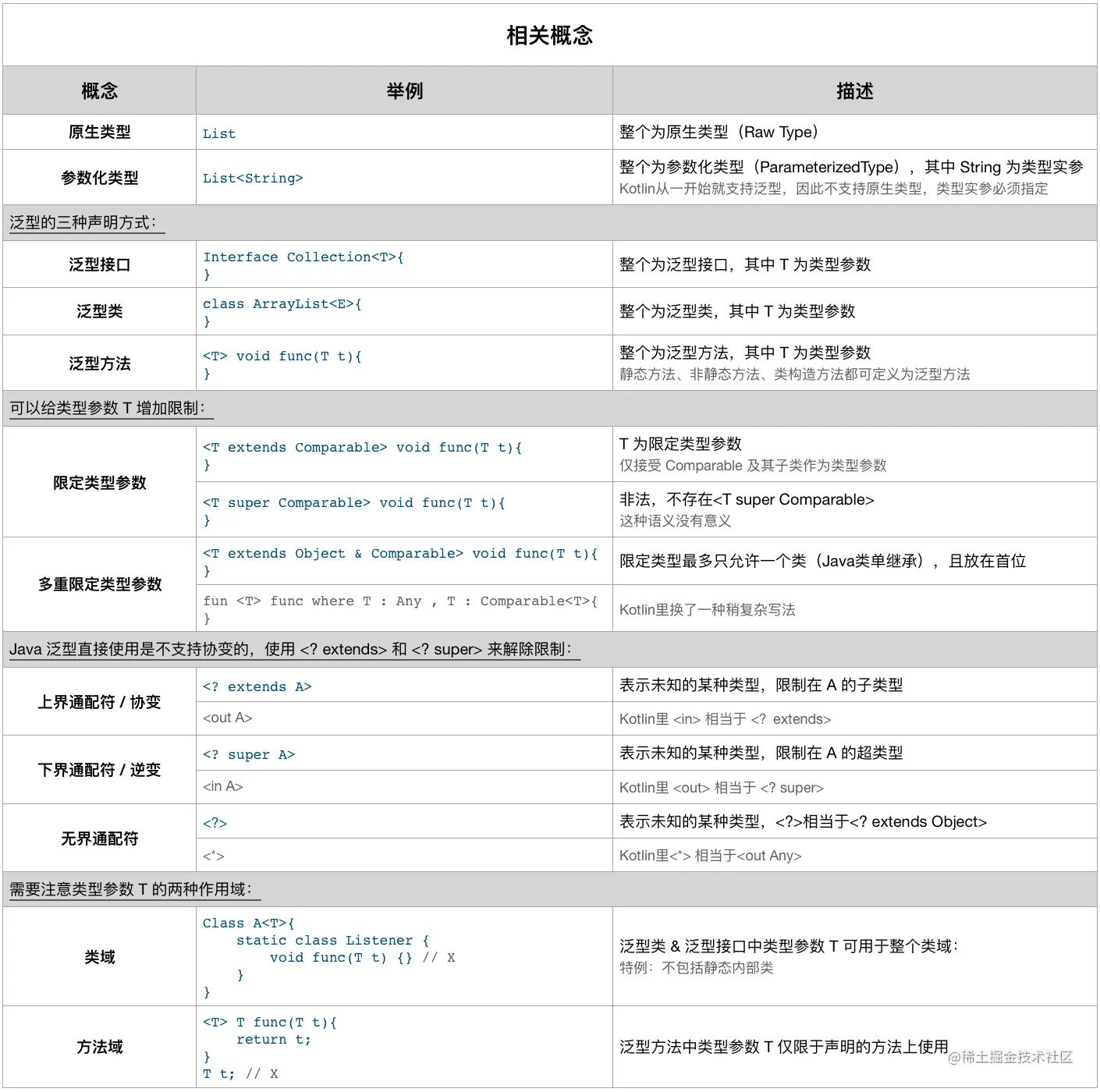
1. 泛型的本质
本质是参数化类型:ArrayList<String> strings = new ArrayList<>();
(1)保证了类型的安全性
在没有泛型之前,从集合中读取到的每一个对象都必须进行类型转换,如果不小心插入了错误的类型对象,在运行时的转换处理就会出错。
(2) 消除强制转换
泛型的一个附带好处是,消除源代码中的许多强制类型转换,不确定的类型转换为确定的类型,这使得代码更加可读,并且减少了出错机会。
(3)避免了不必要的装箱、拆箱操作,提高程序的性能
在非泛型编程中,将筒单类型作为Object传递时会引起Boxing(装箱)和Unboxing(拆箱)操作,这两个过程都是具有很大开销的。引入泛型后,就不必进行Boxing和Unboxing操作了,所以运行效率相对较高,特别在对集合操作非常频繁的系统中,这个特点带来的性能提升更加明显。
泛型变量固定了类型,使用的时候就已经知道是值类型还是引用类型,避免了不必要的装箱、拆箱操作。
(4)提高了代码的重用性。
2. 泛型的使用
泛型有三种使用方式,分别为:泛型类、泛型接口和泛型方法。
常见泛型参数名称有如下:
E:Element (在集合中使用,因为集合中存放的是元素)T:Type(Java 类)K:Key(键)V:Value(值)N:Number(数值类型)?:表示不确定的java类型
(1)泛型类:把泛型定义在类上
public class 类名 <泛型类型1,...> {
}
泛型参数类型规范:
1. T:任意类型 type
2. E:集合中元素的类型 element
3. K:key-value形式 key
4. V:key-value形式 value(2)泛型接口:把泛型定义在接口上
public interface GenericsInteface<T> {
public abstract void add(T t);
}(3)泛型方法:把泛型定义在方法上
深入理解泛型(经典详解):泛型方法详解、类型擦除、通配符的使用、泛型类的应用
修饰符 <代表泛型的变量> 返回值类型 方法名(参数){
}
/**
*
* @param t 传入泛型的参数
* @param <T> 泛型的类型
* @return T 返回值为T类型
* 说明:
* 1)public 与 返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。
* 2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
* 3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
* 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E等形式的参数常用于表示泛型。
*/
/*
<T> T可以传入任何类型的list
关于参数T的说明:
第一个T表示<T>是一个泛型
第二个T表示方法返回的是T类型的数据
第三个T表示集合List传入的数据是T类型
*/
public <T> T genercMethod(T t){
System.out.println(t.getClass());
System.out.println(t);
return t;
}3. 泛型通配符
// 1:表示类型参数可以是任何类型
public class Apple<?>{}
// 2:表示类型参数必须是A或者是A的子类
public class Apple<T extends A>{}
// 3: 表示类型参数必须是A或者是A的超类型
public class Apple<T supers A>{}泛型擦除:
虽然ArrayList<String>和ArrayList<Integer>在编译时是不同的类型,但是在编译完成后都被编译器简化成了ArrayList,这一现象,被称为泛型的类型擦除(Type Erasure)。泛型的本质是参数化类型,而类型擦除使得类型参数只存在于编译期,在运行时,jvm是并不知道泛型的存在的。
为什么要进行泛型的类型擦除呢?
查阅的一些资料中,解释说类型擦除的主要目的是避免过多的创建类而造成的运行时的过度消耗。试想一下,如果用List<A>表示一个类型,再用List<B>表示另一个类型,以此类推,无疑会引起类型的数量爆炸
20. 不能在循环集合的时候删除元素
- 普通for循环,可以删除,但是索引要--
- 迭代器,可以删除,但是必须使用迭代器自身的remove方法,否则会出现并发修改异常
- 增强for循环不能删除
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("b");
list.add("c");
list.add("d");
list.add("b");
//普通for循环删除,索引要--
/*for (int i = 0; i < list.size(); i++) {
if("b".equals(list.get(i))) {
list.remove(i--); //通过索引删除元素
}
}*/
//迭代器删除
/*Iterator<String> it = list.iterator();
while(it.hasNext()) {
if("b".equals(it.next())) {
// list.remove("b"); //不能用集合的删除方法,会报并发修改异常
it.remove();
}
}*/
/*for(Iterator<String> it2 = list.iterator(); it2.hasNext();) {
if("b".equals(it2.next())) {
it2.remove();
}
}*/
//增强for循环,不能删除,只能遍历
for (String String : list) {
if("b".equals(String)) {
list.remove("b");
}
}
System.out.println(list);
}21. TreeSet 保证元素唯一和自然排序的原理
二叉树——小的存储在左边(负数),大的存储在右边(正数),相等就不存(返回0)。
compareTo方法,在TreeSet集合中如何存储元素取决于CopareTo方法的返回值
1.返回0,集合中只有一个元素。通过比较不存储。
2.返回-1,存储在根元素左边。集合倒序
3.返回+1,集合怎么存就怎么取
1.特点
- TreeSet是用来排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列
2.使用方式
- a.自然顺序(Comparable)
- TreeSet类的add()方法中会把存入的对象提升为Comparable类型
- 调用对象的compareTo()方法和集合中的对象比较
- 根据compareTo()方法返回的结果进行存储
- b.比较器顺序(Comparator)
- 创建TreeSet的时候可以制定 一个Comparator
- 如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
- add()方法内部会自动调用Comparator接口中compare()方法排序
- 调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
- c.两种方式的区别
- TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
- TreeSet如果传入Comparator, 就优先按照Comparator进行排序
21. Comparable & Comparator的区别
(1)对比
| 参数 | Comparable | Comparator |
|---|---|---|
| 排序逻辑 | 排序逻辑必须在待排序对象的类中 | 排序逻辑在另一个实现 |
| 实现 | 实现Comparable接口 | 实现Comparator接口 |
| 排序方法 | int compareTo(Object o1) | int compare(Object o1,Object o2) |
| 触发排序 | Collections.sort(List) | Collections.sort(List, Comparator) |
| 所在包 | java.lang.Comparable | java.util.Comparator |
(2)Comparable
自然排序Comparable可以认为是一种内部比较器,一般情况下在类定义时实现Comparable接口,重写compareTo方法实现排序,返回值为int类型共有三种情况:
- 当前对象大于传入对象,返回正整数。
- 当前对象小于传入对象,返回负整数。
- 当前对象等于传入对象,返回0。
若当前对象x = 3,传入对象y = 5,返回值为 -1,认为x < y。排列结果由小到大,即为 3,5,实现了升序排列若当前对象x = 5,传入对象y = 3,返回值为1,认为x > y。排列结果由小到大,即为5,3,实现了降序排列
当返回正数的时候就会调换位置
public class Student implements Comparable<Student>{
private String name;
private int age;
public String getName() {return name;}
public void setName(String name) {this.name = name;}
public int getAge() {return age;}
public void setAge(int age) {this.age = age;}
public int compareTo(Student s){
//按照年龄大小排序
int num = this.age - s.age;//升序
//int num = s.age - this.age;//降序
//年龄一样时,按照姓名字母顺序排序
int num2 =num== 0 ? this.name.compareTo(s.name):num;
return num2;//当返回正数的时候就会调换位置
}
}(3)Comparator
比较器排序Comparator一般采用内部类的方式实现,需要重写compare方法实现排序。返回值为int类型共有三种情况:
- o1 > o2,返回正整数。
- o1 < o2,返回负整数。
- o1 = o2,返回0。
若o1中x = 3,o2中y = 5,返回值为 -1,认为x < y。排列结果由小到大,即为 3,5,实现了升序排列若o1中x = 3,o2中y = 5,返回值为1,认为x > y。排列结果由小到大,即为5,3,实现了降序排列
当返回正数的时候就会调换位置
//内部类实现Comparator接口重写compare方法,实现按年龄升序排列
class StudentCom implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge();//当返回正数的时候就会调换位置
}
}
//内部类实现Comparator接口重写compare方法,实现按年龄降序排列
class StudentComDesc implements Comparator<Student> {
@Override
public int compare(Student o1 14, Student o2 12) {
return o2.getAge() - o1.getAge();//当返回正数的时候就会调换位置
}
}22. finally与return的执行顺序
- 当 try 代码块和 catch 代码块中有 return 语句时,finally 仍然会被执行;
- 执行 try 代码块或 catch 代码块中的 return 语句之前,都会先执行 finally 语句;
- finally代码块中的return语句会覆盖try或catch中的return, finally中最好不要出现return;
- finally中没有return语句的情况下,对变量进行修改:return语句中是基本数据类型,则finally中对变量进行操作不会改变其值;return语句中是引用数据类型,finally中则会修改里面的数据;
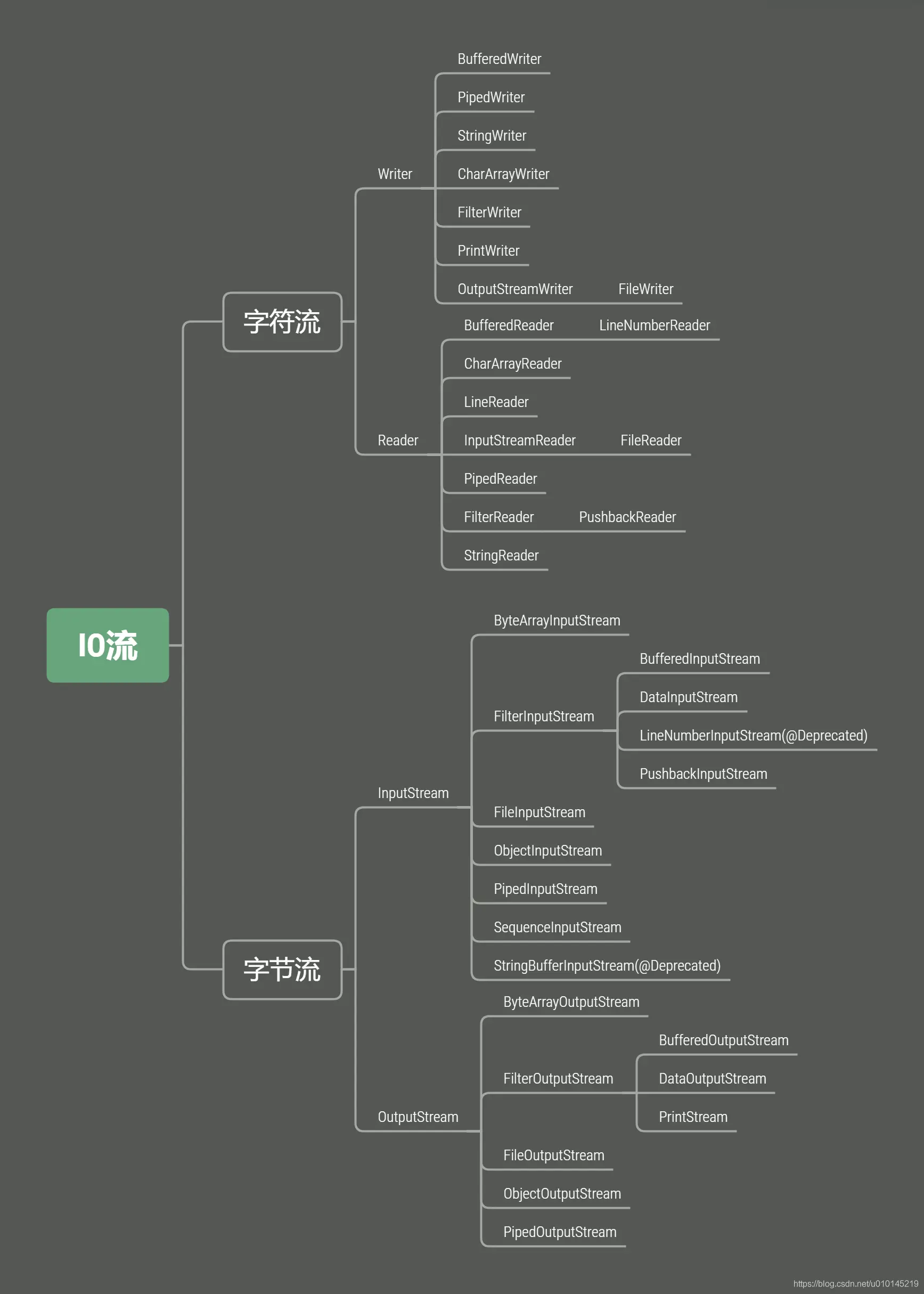
23. IO流
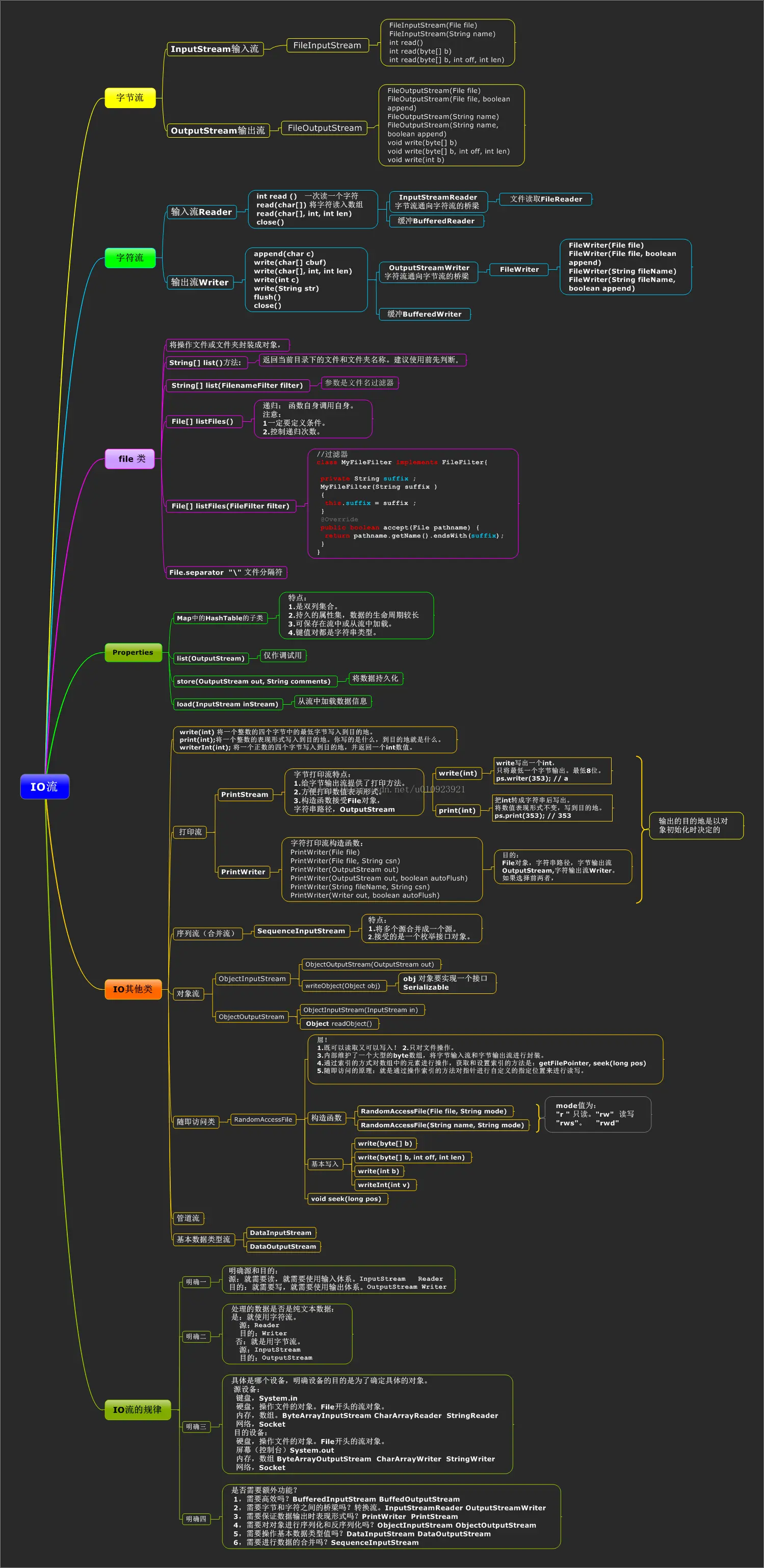
(1)io流分类
(2)io流简单使用
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("视频.avi");
FileOutputStream fos = new FileOutputStream("copy.avi");
byte[] arr = new byte[1024 * 8];
int len;
while((len = fis.read(arr)) != -1) { //忘记写arr,返回的是码表值
fos.write(arr,0,len);
}
fis.close();
fos.close();
}(3)InputStream.available()获取流大小问题
public static void main(String[] args) throws Exception {
String path = "https://t7.baidu.com/it/u=2168645659,3174029352&fm=193&f=GIF";
URLConnection urlConnection = new URL(path).openConnection();
//此连接的URL引用的资源的内容长度,如果内容长度未知,或者内容长度大于Integer.MAX_VALUE,则为-1
int contentLength = urlConnection.getContentLength();
System.out.println(contentLength);
InputStream inputStream = urlConnection.getInputStream();
//inputStream.available()可以在没有阻塞的情况下从此输入流中读取(或跳过)的字节数的估计值
System.out.println("in.available()="+inputStream.available()); //in.available()=15865
byte[] bytes = IOUtils.toByteArray(inputStream);
System.out.println("toByteArray数组大小="+bytes.length);//toByteArray数组大小=169243
//先开后关,先开的输入流,再开的输出流,通过读取输入流写入输出流中,那么应该先关输出流,再关输入流
//先关外层,再关内层
inputStream.close();
}上面的InputStream.available()是从网络中获取数据,由于存在着网络延迟等因素,所以会造成.available()的大小和实际的大小不一致,应该用urlConnection.getContentLength();获取,或者将其转换为字节流byteArrayInputStream然后在获取.available();
(4)IO流的关闭
- 使用装饰流时,只需要关闭最后面的装饰流即可,装饰流是指通过装饰模式实现的java流,又称为包装流,装饰流关闭时会调用原生流关闭;
- 先开后关,先开的输入流,再开的输出流,通过读取输入流写入输出流中,那么应该先关输出流,再关输入流;
- 内存流可以不用关闭,ByteArrayOutputStream和ByteArrayInputStream其实是伪装成流的字节数组(把它们当成字节数据来看就好了),他们不会锁定任何文件句柄和端口,如果不再被使用,字节数组会被垃圾回收掉,所以不需要关闭;
try (OutputStream out = new FileOutputStream("")) { *// ...操作流代码* } catch (Exception e) { e.printStackTrace(); }
24. Java异或
异或是一种基于二进制的位运算,用符号XOR或者^表示,其运算法则是对运算符两侧数的每一个二进制位同值则取0,异值则取1. 简单理解就是不进位加法,如1+1=0,0+0=0,1+0=1. For example: 3^5 = 6 转成二进制后就是 0011 ^ 0101 二号位和三号位都是异值取1 末尾两个1同值取零,所以3^5 = 0110 = 6
应用举例
1-1000放在含有1001个元素的数组中,只有唯一的一个元素值重复,其它均只出现 一次。每个数组元素只能访问一次,设计一个算法,将它找出来;不用辅助存储空 间,能否设计一个算法实现? 解法一、显然已经有人提出了一个比较精彩的解法,将所有数加起来,减去1+2+…+1000的和。 这个算法已经足够完美了,相信出题者的标准答案也就是这个算法,唯一的问题是,如果数列过大,则可能会导致溢出。 解法二、异或就没有这个问题,并且性能更好。 将所有的数全部异或,得到的结果与123…1000的结果进行异或,得到的结果就是重复数。 但是这个算法虽然很简单,但证明起来并不是一件容易的事情。这与异或运算的几个特性有关系。 首先是异或运算满足交换律、结合律。 所以,12…n…n…1000,无论这两个n出现在什么位置,都可以转换成为12…1000(nn)的形式。 其次,对于任何数x,都有xx=0,x0=x。 所以12…n…n…^1000 = 12…1000(n^n)= 12…10000 = 12…^1000(即序列中除了n的所有数的异或)。 令,12…^1000(序列中不包含n)的结果为T 则12…1000(序列中包含n)的结果就是Tn。 T(Tn)=n。 所以,将所有的数全部异或,得到的结果与123…1000的结果进行异或,得到的结果就是重复数。 当然有人会说,1+2+…+1000的结果有高斯定律可以快速计算,但实际上12…^1000的结果也是有规律的,算法比高斯定律还该简单的多。
google面试题的变形:一个数组存放若干整数,一个数出现奇数次,其余数均出现偶数次,找出这个出现奇数次的数?
@Test
public void fun() {
int a[] = { 22, 38,38, 22,22, 4, 4, 11, 11 };
int temp = 0;
for (int i = 0; i < a.length; i++) {
temp ^= a[i];
}
System.out.println(temp);
}解法有很多,但是最好的和上面一样,就是把所有数异或,最后结果就是要找的,原理同上!!
其他用途示例
这样可以实现不引人第三个变量实现交换,但是进行的计算相对第三个变量多,所以效率会低一些。 关于其他的方法还有:int a=5,b=10; a=a+b; //a=15,b=10 b=a-b; //a=15,b=5 a=a-b; //a=10,b=5 但是这样做有一个缺陷,假设它运行在vc6环境中,那么int的大小是4 Bytes,所以int变量所存放的最大值是2^31-1即2147483647,如果我们令a的值为2147483000,b的值为1000000000,那么a和b相加就越界了。 事实上,从实际的运行统计上看,我们发现要交换的两个变量,是同号的概率很大,而且,他们之间相减,越界的情况也很少,因此我们可以把上面的加减法互换,这样使得程序出错的概率减少: int a=5,b=10; a -= b; //a=-5,b=10 b += a; //b=5,a=-5 a = b - a; //a=10,b=5 通过以上运算,a和b中的值就进行了交换。表面上看起来很简单,但是不容易想到,尤其是在习惯引入第三变量的算法之后。 它的原理是:把a、b看做数轴上的点,围绕两点间的距离来进行计算。 具体过程:第一句“a-=b”求出ab两点的距离,并且将其保存在a中;第二句“b+=a”求出a到原点的距离(b到原点的距离与ab两点距离之差),并且将其保存在b中;第三句“a+=b”求出b到原点的距离(a到原点距离与ab两点距离之和),并且将其保存在a中。完成交换。
25. Properties类简介
Properties类继承自Hashtable,key-value格式可以当map来使用
1. getProperty ( String key),用指定的键在此属性列表中搜索属性。也就是通过参数 key ,得到 key 所对应的 value。
2. load ( InputStream inStream),从输入流中读取属性列表(键和元素对)。通过对指定的文件(比如说上面的 test.properties 文件)进行装载来获取该文件中的所有键 - 值对。以供 getProperty ( String key) 来搜索。
3. setProperty ( String key, String value) ,调用 Hashtable 的方法 put 。他通过调用基类的put方法来设置 键 - 值对。
4. store ( OutputStream out, String comments),以适合使用 load 方法加载到 Properties 表中的格式,将此 Properties 表中的属性列表(键和元素对)写入输出流。与 load 方法相反,该方法将键 - 值对写入到指定的文件中去。
5. clear (),清除所有装载的 键 - 值对。该方法在基类中提供。26. 反射
1. 获取Class对象的三种方式
在运行期间,一个类,只有一个Class对象产生。
三种方式常用第三种,第一种对象都有了还要反射干什么;
第二种需要导入类的包,依赖太强,不导包就抛编译错误;
一般都第三种,一个字符串可以传入也可写在配置文件中等多种方法。
(1)Object ——> getClass();
Student stu1 = new Student(); //new 产生一个Student对象,一个Class对象。
Class stuClass = stu1.getClass(); //获取Class对象
System.out.println(stuClass.getName());(2)任何数据类型(包括基本数据类型)都有一个“静态”的class属性 ;
//第二种方式获取Class对象
Class stuClass2 = Student.class;
//判断第一种方式获取的Class对象和第二种方式获取的是否是同一个
System.out.println(stuClass == stuClass2);(3) 通过Class类的静态方法:forName(String className)(常用)
//注意此字符串必须是真实路径,就是带包名的类路径,包名.类名
Class stuClass3 = Class.forName("fanshe.Student");
//判断三种方式是否获取的是同一个Class对象
System.out.println(stuClass3 == stuClass2);2. 通过反射获取构造方法并使用
学生类:
package fanshe;
public class Student {
//---------------构造方法-------------------
//(默认的构造方法)
Student(String str){
System.out.println("(默认)的构造方法 s = " + str);
}
//无参构造方法
public Student(){
System.out.println("调用了公有、无参构造方法执行了。。。");
}
//有一个参数的构造方法
public Student(char name){
System.out.println("姓名:" + name);
}
//有多个参数的构造方法
public Student(String name ,int age){
System.out.println("姓名:"+name+"年龄:"+ age);//这的执行效率有问题,以后解决。
}
//受保护的构造方法
protected Student(boolean n){
System.out.println("受保护的构造方法 n = " + n);
}
//私有构造方法
private Student(int age){
System.out.println("私有的构造方法 年龄:"+ age);
}
}获取构造方法:
(1)批量的方法:
- public Constructor[] getConstructors():所有"公有的"构造方法
- public Constructor[] getDeclaredConstructors():获取所有的构造方法(包括私有、受保护、默认、公有)
(2)获取单个的方法:
- public Constructor getConstructor(Class... parameterTypes):获取单个的"公有的"构造方法:
- public Constructor getDeclaredConstructor(Class... parameterTypes):获取"某个构造方法"可以是私有的,或受保护、默认、公有;
(3)调用构造方法:
- Constructor-->newInstance(Object... initargs)
测试类:
package fanshe;
import java.lang.reflect.Constructor;
public class Constructors {
public static void main(String[] args) throws Exception {
//1.加载Class对象
Class clazz = Class.forName("fanshe.Student");
//2.获取所有公有构造方法
System.out.println("*****所有公有构造方法*****");
Constructor[] conArray = clazz.getConstructors();
for(Constructor c : conArray){
System.out.println(c);
}
System.out.println("*****所有的构造方法(包括:私有、受保护、默认、公有)*****");
conArray = clazz.getDeclaredConstructors();
for(Constructor c : conArray){
System.out.println(c);
}
System.out.println("*****获取公有、无参的构造方法*****");
Constructor con = clazz.getConstructor(null);
//1>、因为是无参的构造方法所以类型是一个null,不写也可以:这里需要的是一个参数的类型,切记是类型
//2>、返回的是描述这个无参构造函数的类对象。
System.out.println("con = " + con);
//调用构造方法
Object obj = con.newInstance();
// System.out.println("obj = " + obj);
// Student stu = (Student)obj;
System.out.println("*****获取私有构造方法,并调用*****");
con = clazz.getDeclaredConstructor(char.class);
System.out.println(con);
//调用构造方法
con.setAccessible(true);//暴力访问(忽略掉访问修饰符)
obj = con.newInstance('男');
}
}控制台输出:
********所有公有构造方法********
public fanshe.Student(java.lang.String,int)
public fanshe.Student(char)
public fanshe.Student()
******所有的构造方法(包括:私有、受保护、默认、公有)******
private fanshe.Student(int)
protected fanshe.Student(boolean)
public fanshe.Student(java.lang.String,int)
public fanshe.Student(char)
public fanshe.Student()
fanshe.Student(java.lang.String)
*******获取公有、无参的构造方法******
con = public fanshe.Student()
调用了公有、无参构造方法执行了。。。
******获取私有构造方法,并调用******
public fanshe.Student(char)
姓名:男3. 获取成员变量并调用
student类:
package fanshe.field;
public class Student {
public Student(){
}
//**********字段*************//
public String name;
protected int age;
char sex;
private String phoneNum;
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + ", sex=" + sex
+ ", phoneNum=" + phoneNum + "]";
}
}获取成员变量并调用:
1.批量的
- Field[] getFields():获取所有的"公有字段"
- Field[] getDeclaredFields():获取所有字段,包括:私有、受保护、默认、公有;2.获取单个的:
- 1).public Field getField(String fieldName):获取某个"公有的"字段;
- 2).public Field getDeclaredField(String fieldName):获取某个字段(可以是私有的)
设置字段的值:
- Field --> public void set(Object obj,Object value):参数说明:
- 1.obj:要设置的字段所在的对象;
- 2.value:要为字段设置的值;
测试类:
package fanshe.field;
import java.lang.reflect.Field;
public class Fields {
public static void main(String[] args) throws Exception {
//1.获取Class对象
Class stuClass = Class.forName("fanshe.field.Student");
//2.获取字段
System.out.println("*****获取所有公有的字段*****");
Field[] fieldArray = stuClass.getFields();
for(Field f : fieldArray){
System.out.println(f);
}
System.out.println("*****获取所有的字段(包括私有、受保护、默认的)*****");
fieldArray = stuClass.getDeclaredFields();
for(Field f : fieldArray){
System.out.println(f);
}
System.out.println("*****获取公有字段**并调用*****");
Field f = stuClass.getField("name");
System.out.println(f);
//获取一个对象
Object obj = stuClass.getConstructor().newInstance();
//产生Student对象--》Student stu = new Student();
//为字段设置值
f.set(obj, "刘德华");//为Student对象中的name属性赋值--》stu.name = "刘德华"
//验证
Student stu = (Student)obj;
System.out.println("验证姓名:" + stu.name);
System.out.println("*****获取私有字段****并调用*****");
f = stuClass.getDeclaredField("phoneNum");
System.out.println(f);
f.setAccessible(true);//暴力反射,解除私有限定
f.set(obj, "18888889999");
System.out.println("验证电话:" + stu);
}
}控制台输出:
************获取所有公有的字段*********
public java.lang.String fanshe.field.Student.name
************获取所有的字段(包括私有、受保护、默认的)********
public java.lang.String fanshe.field.Student.name
protected int fanshe.field.Student.age
char fanshe.field.Student.sex
private java.lang.String fanshe.field.Student.phoneNum
*************获取公有字段**并调用***************
public java.lang.String fanshe.field.Student.name
验证姓名:刘德华
**************获取私有字段****并调用*************
private java.lang.String fanshe.field.Student.phoneNum
验证电话:Student [name=刘德华, age=0, sex=4. 获取成员方法并调用
student类:
package fanshe.method;
public class Student {
//**************成员方法***************//
public void show1(String s){
System.out.println("调用了:公有的,String参数的show1(): s = " + s);
}
protected void show2(){
System.out.println("调用了:受保护的,无参的show2()");
}
void show3(){
System.out.println("调用了:默认的,无参的show3()");
}
private String show4(int age){
System.out.println("调用了,私有的,并且有返回值的,int参数的show4(): age = " + age);
return "abcd";
}
}获取成员方法并调用:
1.获取批量的:
- public Method[] getMethods():获取所有"公有方法";(包含了父类的方法也包含Object类)
- public Method[] getDeclaredMethods():获取所有的成员方法,包括私有的(不包括继承的)
2.获取单个的:
- public Method getMethod(String name,Class<?>... parameterTypes):
- public Method getDeclaredMethod(String name,Class<?>... parameterTypes) 参数:name : 方法名; Class ... : 形参的Class类型对象
调用方法:
- Method --> public Object invoke(Object obj,Object... args): 参数说明:obj : 要调用方法的对象; args:调用方式时所传递的实参;
测试类:
package fanshe.method;
import java.lang.reflect.Method;
public class MethodClass {
public static void main(String[] args) throws Exception {
//1.获取Class对象
Class stuClass = Class.forName("fanshe.method.Student");
//2.获取所有公有方法
System.out.println("**********获取所有的”公有“方法************");
stuClass.getMethods();
Method[] methodArray = stuClass.getMethods();
for(Method m : methodArray){
System.out.println(m);
}
System.out.println("*********获取所有的方法,包括私有的*********");
methodArray = stuClass.getDeclaredMethods();
for(Method m : methodArray){
System.out.println(m);
}
System.out.println("*********获取公有的show1()方法*************");
Method m = stuClass.getMethod("show1", String.class);
System.out.println(m);
//实例化一个Student对象
Object obj = stuClass.getConstructor().newInstance();
m.invoke(obj, "刘德华");
System.out.println("***********获取私有的show4()方法********");
m = stuClass.getDeclaredMethod("show4", int.class);
System.out.println(m);
//解除私有限定
m.setAccessible(true);
//需要两个参数,一个是要调用的对象(获取有反射),一个是实参
Object result = m.invoke(obj, 20);
System.out.println("返回值:" + result);
}
}控制台输出:
***************获取所有的”公有“方法*******************
public void fanshe.method.Student.show1(java.lang.String)
public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
public final void java.lang.Object.wait() throws java.lang.InterruptedException
public boolean java.lang.Object.equals(java.lang.Object)
public java.lang.String java.lang.Object.toString()
public native int java.lang.Object.hashCode()
public final native java.lang.Class java.lang.Object.getClass()
public final native void java.lang.Object.notify()
public final native void java.lang.Object.notifyAll()
***************获取所有的方法,包括私有的*******************
public void fanshe.method.Student.show1(java.lang.String)
private java.lang.String fanshe.method.Student.show4(int)
protected void fanshe.method.Student.show2()
void fanshe.method.Student.show3()
***************获取公有的show1()方法*******************
public void fanshe.method.Student.show1(java.lang.String)
调用了:公有的,String参数的show1(): s = 刘德华
***************获取私有的show4()方法******************
private java.lang.String fanshe.method.Student.show4(int)
调用了,私有的,并且有返回值的,int参数的show4(): age = 20
返回值:abcd5. 反射main方法
student类:
package fanshe.main;
public class Student {
public static void main(String[] args) {
System.out.println("main方法执行了。。。");
}
}测试类:
package fanshe.main;
import java.lang.reflect.Method;
/**
* 获取Student类的main方法、不要与当前的main方法搞混了
*/
public class Main {
public static void main(String[] args) {
try {
//1、获取Student对象的字节码
Class clazz = Class.forName("fanshe.main.Student");
//2、获取main方法
Method methodMain = clazz.getMethod("main", String[].class);//第一个参数:方法名称,第二个参数:方法形参的类型,
//3、调用main方法
// methodMain.invoke(null, new String[]{"a","b","c"});
//第一个参数,对象类型,因为方法是static静态的,所以为null可以,第二个参数是String数组,这里要注意在jdk1.4时是数组,jdk1.5之后是可变参数
//这里拆的时候将 new String[]{"a","b","c"} 拆成3个对象。。。所以需要将它强转。
methodMain.invoke(null, (Object)new String[]{"a","b","c"});//方式一
// methodMain.invoke(null, new Object[]{new String[]{"a","b","c"}});//方式二
} catch (Exception e) {
e.printStackTrace();
}
}
}6. 通过反射运行配置文件内容
student类:
public class Student {
public void show(){
System.out.println("is show()");
}
}配置文件以txt文件为例子(pro.txt):
className = cn.fanshe.Student
methodName = show测试类:
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.Properties;
/*
* 我们利用反射和配置文件,可以使:应用程序更新时,对源码无需进行任何修改
* 我们只需要将新类发送给客户端,并修改配置文件即可
*/
public class Demo {
public static void main(String[] args) throws Exception {
//通过反射获取Class对象
Class stuClass = Class.forName(getValue("className"));//"cn.fanshe.Student"
//2获取show()方法
Method m = stuClass.getMethod(getValue("methodName"));//show
//3.调用show()方法
m.invoke(stuClass.getConstructor().newInstance());
}
//此方法接收一个key,在配置文件中获取相应的value
public static String getValue(String key) throws IOException{
Properties pro = new Properties();//获取配置文件的对象
FileReader in = new FileReader("pro.txt");//获取输入流
pro.load(in);//将流加载到配置文件对象中
in.close();
return pro.getProperty(key);//返回根据key获取的value值
}
}
控制台输出:
is show()7. 通过反射越过泛型检查
泛型用在编译期,编译过后泛型擦除(消失掉)。所以是可以通过反射越过泛型检查的
测试类:
import java.lang.reflect.Method;
import java.util.ArrayList;
/*
* 通过反射越过泛型检查
*
* 例如:有一个String泛型的集合,怎样能向这个集合中添加一个Integer类型的值?
*/
public class Demo {
public static void main(String[] args) throws Exception{
ArrayList<String> strList = new ArrayList<>();
strList.add("aaa");
strList.add("bbb");
//strList.add(100);
//获取ArrayList的Class对象,反向的调用add()方法,添加数据
Class listClass = strList.getClass(); //得到 strList 对象的字节码 对象
//获取add()方法
Method m = listClass.getMethod("add", Object.class);
//调用add()方法
m.invoke(strList, 100);
//遍历集合
for(Object obj : strList){
System.out.println(obj);
}
}
}控制台输出:
aaa
bbb
10027. 动态代理
Java中两种常见的动态代理方式:JDK原生动态代理和CGLIB动态代理
动态代理在Java中有着广泛的应用,比如Spring AOP、Hibernate数据查询、测试框架的后端mock、RPC远程调用、Java注解对象获取、日志、用户鉴权、全局性异常处理、性能监控,甚至事务处理等。
1. 概念
代理模式:给某一个对象提供一个代理,并由代理对象来控制对真实对象的访问。代理模式是一种结构型设计模式
代理模式角色分为 3 种:
- Subject(抽象主题角色):定义代理类和真实主题的公共对外方法,也是代理类代理真实主题的方法;
- RealSubject(真实主题角色):真正实现业务逻辑的类;
- Proxy(代理主题角色):用来代理和封装真实主题;
如果根据字节码的创建时机来分类,可以分为静态代理和动态代理:
- 所谓静态也就是在程序运行前就已经存在代理类的字节码文件,代理类和真实主题角色的关系在运行前就确定了。
- 而动态代理的源码是在程序运行期间由JVM根据反射等机制动态的生成,所以在运行前并不存在代理类的字节码文件
2. 静态代理
//1. 编写一个接口 UserService ,以及该接口的一个实现类 UserServiceImpl
public interface UserService {
public void select();
public void update();
}
public class UserServiceImpl implements UserService {
public void select() {
System.out.println("查询 selectById");
}
public void update() {
System.out.println("更新 update");
}
}
//2. 通过静态代理对 UserServiceImpl 进行功能增强,在调用select和update之前记录一些日志。写一个代理类 UserServiceProxy,代理类需要实现 UserService
public class UserServiceProxy implements UserService {
private UserService target; // 被代理的对象
public UserServiceProxy(UserService target) {
this.target = target;
}
public void select() {
before();
target.select(); // 这里才实际调用真实主题角色的方法
after();
}
public void update() {
before();
target.update(); // 这里才实际调用真实主题角色的方法
after();
}
private void before() { // 在执行方法之前执行
System.out.println(String.format("log start time [%s] ", new Date()));
}
private void after() { // 在执行方法之后执行
System.out.println(String.format("log end time [%s] ", new Date()));
}
}
//3. 客户端测试
public class Client1 {
public static void main(String[] args) {
UserService userServiceImpl = new UserServiceImpl();
UserService proxy = new UserServiceProxy(userServiceImpl);
proxy.select();
proxy.update();
}
}静态代理的缺点:
当需要代理多个类的时候,由于代理对象要实现与目标对象一致的接口,有两种方式:
- 只维护一个代理类,由这个代理类实现多个接口,但是这样就导致代理类过于庞大
- 新建多个代理类,每个目标对象对应一个代理类,但是这样会产生过多的代理类
当接口需要增加、删除、修改方法的时候,目标对象与代理类都要同时修改,不易维护。
3. 动态代理
1. 概念
使用场景:
- 设计模式中有一个设计原则是开闭原则,是说对修改关闭对扩展开放,我们在工作中有时会接手很多前人的代码,里面代码逻辑让人摸不着头脑(sometimes the code is really like shit),这时就很难去下手修改代码,那么这时我们就可以通过代理对类进行增强。
- 我们在使用RPC框架的时候,框架本身并不能提前知道各个业务方要调用哪些接口的哪些方法 。那么这个时候,就可用通过动态代理的方式来建立一个中间人给客户端使用,也方便框架进行搭建逻辑,某种程度上也是客户端代码和框架松耦合的一种表现。
- Spring的AOP机制就是采用动态代理的机制来实现切面编程。统计每个 api 的请求耗时,统一的日志输出,校验被调用的 api 是否已经登录和权限鉴定。
动态代理就是类可以动态的生成,这就涉及到Java虚拟机的类加载机制了
Java虚拟机类加载过程主要分为五个阶段:加载、验证、准备、解析、初始化。其中加载阶段需要完成以下3件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据访问入口
由于虚拟机规范对这3点要求并不具体,所以实际的实现是非常灵活的,关于第1点,获取类的二进制字节流(class字节码)就有很多途径:
- 从ZIP包获取,这是JAR、EAR、WAR等格式的基础
- 从网络中获取,典型的应用是 Applet
- 运行时计算生成,这种场景使用最多的是动态代理技术,在 java.lang.reflect.Proxy 类中,就是用了 ProxyGenerator.generateProxyClass 来为特定接口生成形式为 *$Proxy 的代理类的二进制字节流
- 由其它文件生成,典型应用是JSP,即由JSP文件生成对应的Class类
- 从数据库中获取等等
所以,动态代理就是想办法,根据接口或目标对象,计算出代理类的字节码,然后再加载到JVM中使用。
常见的有2中实现方式:
- 通过实现接口的方式 -> JDK动态代理
- 通过继承类的方式 -> CGLIB动态代理
2. JDK动态代理
JDK动态代理主要涉及两个类:java.lang.reflect.Proxy 和 java.lang.reflect.InvocationHandler,我们仍然通过案例来学习编写一个调用逻辑处理器 LogHandler 类,提供日志增强功能,并实现 InvocationHandler 接口;在 LogHandler 中维护一个目标对象,这个对象是被代理的对象(真实主题角色);在 invoke 方法中编写方法调用的逻辑处理。
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.util.Date;
public class LogHandler implements InvocationHandler {
Object target; // 被代理的对象,实际的方法执行者
public LogHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//增强
before();
Object result = method.invoke(target, args); // 调用 target 的 method 方法
//增强
after();
return result; // 返回方法的执行结果
}
// 调用invoke方法之前执行
private void before() {
System.out.println(String.format("log start time [%s] ", new Date()));
}
// 调用invoke方法之后执行
private void after() {
System.out.println(String.format("log end time [%s] ", new Date()));
}
}编写客户端,获取动态生成的代理类的对象须借助 Proxy 类的 newProxyInstance 方法,具体步骤可见代码和注释
import proxy.UserService;
import proxy.UserServiceImpl;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
public class Client2 {
public static void main(String[] args) throws IllegalAccessException, InstantiationException {
// 设置变量可以保存动态代理类,默认名称以 $Proxy0 格式命名
//System.getProperties().setProperty("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
// 1. 创建被代理的对象,UserService接口的实现类
UserServiceImpl userServiceImpl = new UserServiceImpl();
// 2. 获取对应的 ClassLoader
ClassLoader classLoader = userServiceImpl.getClass().getClassLoader();
// 3. 获取所有接口的Class,这里的UserServiceImpl只实现了一个接口UserService,
Class[] interfaces = userServiceImpl.getClass().getInterfaces();
// 4. 创建一个将传给代理类的调用请求处理器,处理所有的代理对象上的方法调用
//这里创建的是一个自定义的日志处理器,须传入实际的执行对象 userServiceImpl
InvocationHandler logHandler = new LogHandler(userServiceImpl);
/*
5.根据上面提供的信息,创建代理对象 在这个过程中,
a.JDK会通过根据传入的参数信息动态地在内存中创建和.class 文件等同的字节码
b.然后根据相应的字节码转换成对应的class,
c.然后调用newInstance()创建代理实例
*/
UserService proxy = (UserService) Proxy.newProxyInstance(
classLoader, interfaces, logHandler);
// 调用代理的方法
proxy.select();
proxy.update();
// 保存JDK动态代理生成的代理类,类名保存为 UserServiceProxy
// ProxyUtils.generateClassFile(userServiceImpl.getClass(), "UserServiceProxy");
}
}
//运行结果
log start time [Thu Dec 20 16:55:19 CST 2018]
查询 selectById
log end time [Thu Dec 20 16:55:19 CST 2018]
log start time [Thu Dec 20 16:55:19 CST 2018]
更新 update
log end time [Thu Dec 20 16:55:19 CST 2018]InvocationHandler 和 Proxy 的主要方法介绍如下:
java.lang.reflect.InvocationHandler
Object invoke(Object proxy, Method method, Object[] args)定义了代理对象调用方法时希望执行的动作,用于集中处理在动态代理类对象上的方法调用
java.lang.reflect.Proxy
static InvocationHandler getInvocationHandler(Object proxy)用于获取指定代理对象所关联的调用处理器static Class<?> getProxyClass(ClassLoader loader, Class<?>... interfaces)返回指定接口的代理类static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)构造实现指定接口的代理类的一个新实例,所有方法会调用给定处理器对象的 invoke 方法static boolean isProxyClass(Class<?> cl)返回 cl 是否为一个代理类
代理类的调用过程
借助下面的工具类,把代理类保存下来再探个究竟(通过设置环境变量sun.misc.ProxyGenerator.saveGeneratedFiles=true也可以保存代理类)
import sun.misc.ProxyGenerator;
import java.io.FileOutputStream;
import java.io.IOException;
public class ProxyUtils {
/**
* 将根据类信息动态生成的二进制字节码保存到硬盘中,默认的是clazz目录下
* params: clazz 需要生成动态代理类的类
* proxyName: 为动态生成的代理类的名称
*/
public static void generateClassFile(Class clazz, String proxyName) {
// 根据类信息和提供的代理类名称,生成字节码
byte[] classFile = ProxyGenerator.generateProxyClass(proxyName, clazz.getInterfaces());
String paths = clazz.getResource(".").getPath();
System.out.println(paths);
FileOutputStream out = null;
try {
//保留到硬盘中
out = new FileOutputStream(paths + proxyName + ".class");
out.write(classFile);
out.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//然后在 Client2 测试类的main的最后面加入一行代码
// 保存JDK动态代理生成的代理类,类名保存为 UserServiceProxy
ProxyUtils.generateClassFile(userServiceImpl.getClass(), "UserServiceProxy");UserServiceProxy 的代码如下所示:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.lang.reflect.UndeclaredThrowableException;
import proxy.UserService;
public final class UserServiceProxy extends Proxy implements UserService {
private static Method m1;
private static Method m2;
private static Method m4;
private static Method m0;
private static Method m3;
public UserServiceProxy(InvocationHandler var1) throws {
super(var1);
}
public final boolean equals(Object var1) throws {
// 省略...
}
public final String toString() throws {
// 省略...
}
public final void select() throws {
try {
super.h.invoke(this, m4, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
public final int hashCode() throws {
// 省略...
}
public final void update() throws {
try {
super.h.invoke(this, m3, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
static {
try {
m1 = Class.forName("java.lang.Object").getMethod("equals", Class.forName("java.lang.Object"));
m2 = Class.forName("java.lang.Object").getMethod("toString");
m4 = Class.forName("proxy.UserService").getMethod("select");
m0 = Class.forName("java.lang.Object").getMethod("hashCode");
m3 = Class.forName("proxy.UserService").getMethod("update");
} catch (NoSuchMethodException var2) {
throw new NoSuchMethodError(var2.getMessage());
} catch (ClassNotFoundException var3) {
throw new NoClassDefFoundError(var3.getMessage());
}
}
}从 UserServiceProxy 的代码中我们可以发现:
- UserServiceProxy 继承了 Proxy 类,并且实现了被代理的所有接口,以及equals、hashCode、toString等方法
- 由于 UserServiceProxy 继承了 Proxy 类,所以每个代理类都会关联一个 InvocationHandler 方法调用处理器
- 类和所有方法都被 public final 修饰,所以代理类只可被使用,不可以再被继承
- 每个方法都有一个 Method 对象来描述,Method 对象在static静态代码块中创建,以 m + 数字 的格式命名
- 调用方法的时候通过 super.h.invoke(this, m1, (Object[])null); 调用,其中的 super.h.invoke 实际上是在创建代理的时候传递给 Proxy.newProxyInstance 的 LogHandler 对象,它继承 InvocationHandler 类,负责实际的调用处理逻辑
而 LogHandler 的 invoke 方法接收到 method、args 等参数后,进行一些处理,然后通过反射让被代理的对象 target 执行方法
JDK动态代理执行方法调用的过程简图如下: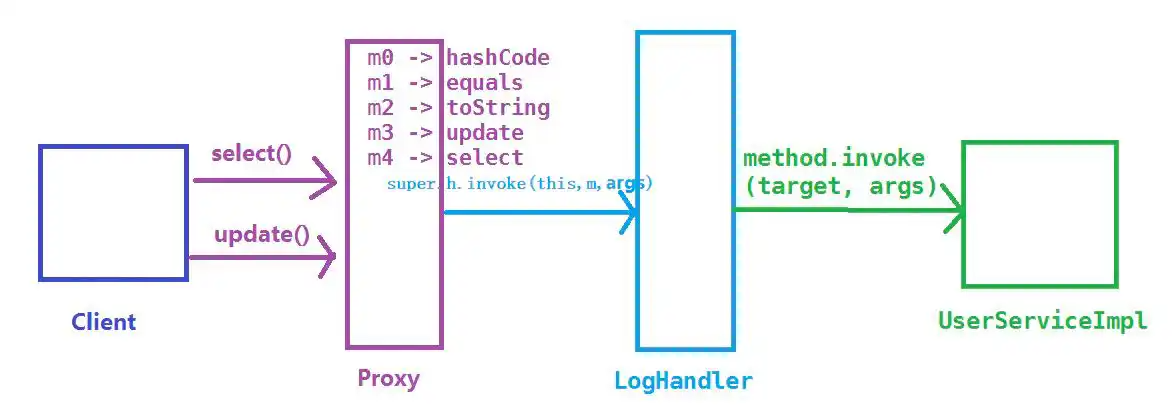
3. CGLIB动态代理
编写一个 LogInterceptor ,继承了 MethodInterceptor,用于方法的拦截回调
public class UserDao {
public void select() {
System.out.println("UserDao 查询 selectById");
}
public void update() {
System.out.println("UserDao 更新 update");
}
}
-------------------------------------------------------------------------------
import java.lang.reflect.Method;
import java.util.Date;
public class LogInterceptor implements MethodInterceptor {
/**
* @param object 表示要进行增强的对象
* @param method 表示拦截的方法
* @param objects 数组表示参数列表,基本数据类型需要传入其包装类型,如int-->Integer、long-Long、double-->Double
* @param methodProxy 表示对方法的代理,invokeSuper方法表示对被代理对象方法的调用
* @return 执行结果
* @throws Throwable
*/
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
before();
Object result = methodProxy.invokeSuper(object, objects); // 注意这里是调用 invokeSuper 而不是 invoke,否则死循环,methodProxy.invokesuper执行的是原始类的方法,method.invoke执行的是子类的方法
after();
return result;
}
private void before() {
System.out.println(String.format("log start time [%s] ", new Date()));
}
private void after() {
System.out.println(String.format("log end time [%s] ", new Date()));
}
}测试:
//测试
public static void main(String[] args) {
LogInterceptor logInterceptor = new LogInterceptor();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(UserDao.class); // 设置超类,cglib是通过继承来实现的
enhancer.setCallback(logInterceptor);
UserDao dao = (UserDao)enhancer.create(); // 创建代理类
dao.update();
dao.select();
}
//运行结果
log start time [Fri Dec 21 00:06:40 CST 2018]
UserDao 查询 selectById
log end time [Fri Dec 21 00:06:40 CST 2018]
log start time [Fri Dec 21 00:06:40 CST 2018]
UserDao 更新 update
log end time [Fri Dec 21 00:06:40 CST 2018]还可以进一步对多个 MethodInterceptor 进行过滤筛选
public class LogInterceptor2 implements MethodInterceptor {
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
before();
Object result = methodProxy.invokeSuper(object, objects);
after();
return result;
}
private void before() {
System.out.println(String.format("log2 start time [%s] ", new Date()));
}
private void after() {
System.out.println(String.format("log2 end time [%s] ", new Date()));
}
}
// 回调过滤器: 在CGLib回调时可以设置对不同方法执行不同的回调逻辑,或者根本不执行回调。
public class DaoFilter implements CallbackFilter {
@Override
public int accept(Method method) {
if ("select".equals(method.getName())) {
return 0; // Callback 列表第1个拦截器
}
return 1; // Callback 列表第2个拦截器,return 2 则为第3个,以此类推
}
}再次测试
public class CglibTest2 {
public static void main(String[] args) {
LogInterceptor logInterceptor = new LogInterceptor();
LogInterceptor2 logInterceptor2 = new LogInterceptor2();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(UserDao.class); // 设置超类,cglib是通过继承来实现的
enhancer.setCallbacks(new Callback[]{logInterceptor, logInterceptor2, NoOp.INSTANCE});
// 设置多个拦截器,NoOp.INSTANCE是一个空拦截器,不做任何处理
enhancer.setCallbackFilter(new DaoFilter());
UserDao proxy = (UserDao) enhancer.create(); // 创建代理类
proxy.select();
proxy.update();
}
}
//运行结果
log start time [Fri Dec 21 00:22:39 CST 2018]
UserDao 查询 selectById
log end time [Fri Dec 21 00:22:39 CST 2018]
log2 start time [Fri Dec 21 00:22:39 CST 2018]
UserDao 更新 update
log2 end time [Fri Dec 21 00:22:39 CST 2018]4. CGlib 对接口实现代理
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import proxy.UserService;
import java.lang.reflect.Method;
/**
* 创建代理类的工厂 该类要实现 MethodInterceptor 接口。
* 该类中完成三样工作:
* (1)声明目标类的成员变量,并创建以目标类对象为参数的构造器。用于接收目标对象
* (2)定义代理的生成方法,用于创建代理对象。方法名是任意的。代理对象即目标类的子类
* (3)定义回调接口方法。对目标类的增强这在这里完成
*/
public class CGLibFactory implements MethodInterceptor {
// 声明目标类的成员变量
private UserService target;
public CGLibFactory(UserService target) {
this.target = target;
}
// 定义代理的生成方法,用于创建代理对象
public UserService myCGLibCreator() {
Enhancer enhancer = new Enhancer();
// 为代理对象设置父类,即指定目标类
enhancer.setSuperclass(UserService.class);
/**
* 设置回调接口对象 注意,只所以在setCallback()方法中可以写上this,
* 是因为MethodIntecepter接口继承自Callback,是其子接口
*/
enhancer.setCallback(this);
return (UserService) enhancer.create();// create用以生成CGLib代理对象
}
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("start invoke " + method.getName());
Object result = method.invoke(target, args);
System.out.println("end invoke " + method.getName());
return result;
}
}4. JDK动态代理与CGLIB动态代理对比
JDK动态代理:基于Java反射机制实现,必须要实现了接口的业务类才能用这种办法生成代理对象。
cglib动态代理:基于ASM机制实现,通过生成业务类的子类作为代理类。
JDK Proxy 的优势:
- 最小化依赖关系,减少依赖意味着简化开发和维护,JDK 本身的支持,可能比 cglib 更加可靠。
- 平滑进行 JDK 版本升级,而字节码类库通常需要进行更新以保证在新版 Java 上能够使用。
- 代码实现简单。
基于类似 cglib 框架的优势:
- 无需实现接口,达到代理类无侵入
- 只操作我们关心的类,而不必为其他相关类增加工作量。
- 高性能
描述动态代理的几种实现方式?分别说出相应的优缺点
代理可以分为 "静态代理" 和 "动态代理",动态代理又分为 "JDK动态代理" 和 "CGLIB动态代理" 实现。静态代理:代理对象和实际对象都继承了同一个接口,在代理对象中指向的是实际对象的实例,这样对外暴露的是代理对象而真正调用的是 Real Object
- 优点:可以很好的保护实际对象的业务逻辑对外暴露,从而提高安全性。
- 缺点:不同的接口要有不同的代理类实现,会很冗余
JDK 动态代理:
为了解决静态代理中,生成大量的代理类造成的冗余;JDK 动态代理只需要实现 InvocationHandler 接口,重写 invoke 方法便可以完成代理的实现,jdk的代理是利用反射生成代理类 Proxyxx.class 代理类字节码,并生成对象 jdk动态代理之所以只能代理接口是因为代理类本身已经extends了Proxy,而java是不允许多重继承的,但是允许实现多个接口。
优点:解决了静态代理中冗余的代理实现类问题。
缺点:JDK 动态代理是基于接口设计实现的,如果没有接口,会抛异常。
CGLIB 代理:
由于 JDK 动态代理限制了只能基于接口设计,而对于没有接口的情况,JDK方式解决不了;CGLib 采用了非常底层的字节码技术,其原理是通过字节码技术为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑,来完成动态代理的实现。实现方式实现 MethodInterceptor 接口,重写 intercept 方法,通过 Enhancer 类的回调方法来实现。但是CGLib在创建代理对象时所花费的时间却比JDK多得多,所以对于单例的对象,因为无需频繁创建对象,用CGLib合适,反之,使用JDK方式要更为合适一些。 同时,由于CGLib由于是采用动态创建子类的方法,对于final方法,无法进行代理。
优点:没有接口也能实现动态代理,而且采用字节码增强技术,性能也不错。
缺点:技术实现相对难理解些。
5. 其他文章
动态代理大揭秘,带你彻底弄清楚动态代理! - 铂赛东 - 博客园 (cnblogs.com)
28. MyBatis中${} 和 #{} 的区别
- #{}是预编译处理,${}是字符串替换。
- MyBatis在处理#{}时,会将SQL中的#{}替换为?号,使用PreparedStatement的set方法来赋值;MyBatis在处理 ${} 时,就是把 ${} 替换成变量的值。
- 使用 #{} 可以有效的防止SQL注入,提高系统安全性。
默认情况下,使用#{}语法,MyBatis会产生PreparedStatement语句,并且安全地设置PreparedStatement参数,这个过程中MyBatis会进行必要的安全检查和转义。例如:
执行SQL:select * from emp where name = #{employeeName}
参数:employeeName=>Smith
解析后执行的SQL:select * from emp where name = ?
执行SQL:Select * from emp where name = ${employeeName}
参数:employeeName传入值为:Smith
解析后执行的SQL:Select * from emp where name =Smith
综上所述,${}方式可能会引发SQL注入的问题,同时也会影响SQL语句的预编译,所以从安全性和性能的角度出发,应尽量使用#{}。当需要直接插入一个不做任何修改的字符串到SQL语句中,例如在ORDER BY后接一个不添加引号的值作为列名,这时候就需要使用${},比如表名。29. Redis相关
(1)Redis的5种数据结构
redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
- 字符串类型 string
- 哈希类型 hash : map格式
- 列表类型 list : linkedlist格式。支持重复元素
- 集合类型 set : 不允许重复元素
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序
(2)Redis操作命令
1. 通用命令:
1. keys * : 查询所有的键
2. type key : 获取键对应的value的类型
3. del key:删除指定的key value- 字符串类型 string
1. 存储: set key value
127.0.0.1:6379> set username zhangsan
OK
2. 获取: get key
127.0.0.1:6379> get username
"zhangsan"
3. 删除: del key
127.0.0.1:6379> del age
(integer) 1- 哈希类型 hash
1. 存储: hset key field value
127.0.0.1:6379> hset myhash username lisi
(integer) 1
127.0.0.1:6379> hset myhash password 123
(integer) 1
2. 获取:
* hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username
"lisi"
* hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash
1) "username"
2) "lisi"
3) "password"
4) "123"
3. 删除: hdel key field
127.0.0.1:6379> hdel myhash username
(integer) 1- 列表类型 list:可以添加一个元素到列表的头部(左边)或者尾部(右边)
1. 添加:
1. lpush key value: 将元素加入列表左表
2. rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a
(integer) 1
127.0.0.1:6379> lpush myList b
(integer) 2
127.0.0.1:6379> rpush myList c
(integer) 3
2. 获取:
* lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1
1) "b"
2) "a"
3) "c"
3. 删除:
* lpop key: 删除列表最左边的元素,并将元素返回
* rpop key: 删除列表最右边的元素,并将元素返回- 集合类型 set : 不允许重复元素
1. 存储:sadd key value
127.0.0.1:6379> sadd myset a
(integer) 1
127.0.0.1:6379> sadd myset a
(integer) 0
2. 获取:smembers key:获取set集合中所有元素
127.0.0.1:6379> smembers myset
1) "a"
3. 删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a
(integer) 1- 有序集合类型 sortedset:不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
1. 存储:zadd key score value
127.0.0.1:6379> zadd mysort 60 zhangsan
(integer) 1
127.0.0.1:6379> zadd mysort 50 lisi
(integer) 1
127.0.0.1:6379> zadd mysort 80 wangwu
(integer) 1
2. 获取:zrange key start end [withscores]
127.0.0.1:6379> zrange mysort 0 -1
1) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "zhangsan"
2) "60"
3) "wangwu"
4) "80"
5) "lisi"
6) "500"
3. 删除:zrem key value
127.0.0.1:6379> zrem mysort lisi
(integer) 130. 网络编程
在展开介绍TCP/IP协议之前,首先介绍一下七层ISO模型。国际标准化组织ISO为了使网络应用更为普及,推出了OSI参考模型,即开放式系统互联(OpenSystem Interconnect)模型,一般都叫OSI参考模型。OSI参考模型是ISO组织在1985年发布的网络互连模型,其含义就是为所有公司使用一个统一的规范来控制网络,这样所有公司遵循相同的通信规范,网络就能互联互通了。
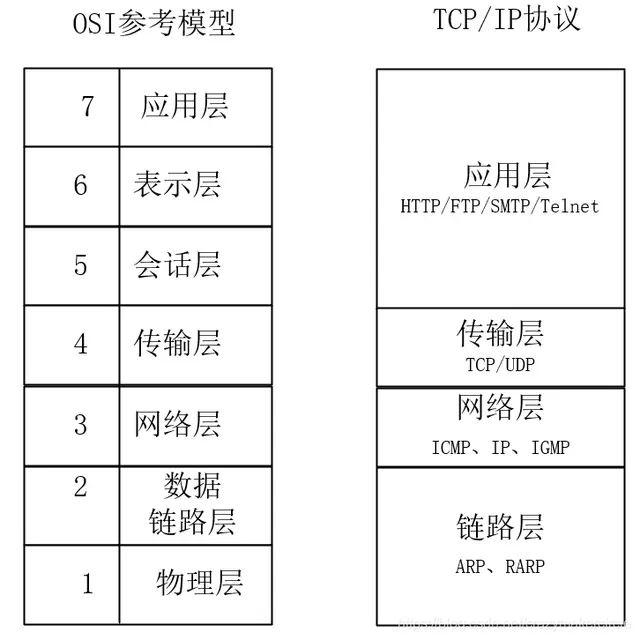
(1)模型框架
OSI模型定义了网络互连的七层框架(物理层、数据链路层、网络层、传输层、会话层、表示层、应用层),每一层实现各自的功能和协议,并完成与相邻层的接口通信。OSI模型各层的通信协议,大致举例如下表所示:
表:OSI模型各层的通信协议举例
| 层级 | 例子 |
|---|---|
| 应用层 | HTTP、SMTP、SNMP、FTP、Telnet、SIP、SSH、NFS、RTSP、XMPP、Whois、ENRP、等 |
| 表示层 | XDR、ASN.1、SMB、AFP、NCP、等 |
| 会话层 | ASAP、SSH、RPC、NetBIOS、ASP、Winsock、BSD Sockets、等 |
| 传输层 | TCP、UDP、TLS、RTP、SCTP、SPX、ATP、IL、等 |
| 网络层 | IP、ICMP、IGMP、IPX、BGP、OSPF、RIP、IGRP、EIGRP、ARP、RARP、X.25、等 |
| 数据链路层 | 以太网、令牌环、HDLC、帧中继、ISDN、ATM、IEEE 802.11、FDDI、PPP、等 |
| 物理层 | 例如铜缆、网线、光缆、无线电等 |
TCP/IP协议是Internet互联网最基本的协议,其在一定程度上参考了七层ISO模型。OSI模型共有七层,从下到上分别是物理层、数据链路层、网络层、运输层、会话层、表示层和应用层。但是这显然是有些复杂的,所以在TCP/IP协议中,七层被简化为了四个层次。TCP/IP模型中的各种协议,依其功能不同,被分别归属到这四层之中,常被视为是简化过后的七层OSI模型。
- 链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。
- 网络层:网络层是整个TCP/IP协议的核心,它主要用于将传输的数据进行分组,将分组数据发送到目标计算机或者网络。
- 运输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。
- 应用层:主要负责应用程序的协议,例如HTTP协议、FTP协议等。
UDP:用户数据报协议(User Datagram Protocol)。UDP是无连接通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
TCP:传输控制协议 (Transmission Control Protocol)。TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。
在TCP连接中必须要明确客户端与服务器端,由客户端向服务端发出连接请求,每次连接的创建都需要经过“三次握手”。
三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
- 第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
- 第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
- 第三次握手,客户端再次向服务器端发送确认信息,确认连接。
(2)TCP
1. 客户端向服务器发送数据
服务端实现:
public class ServerTCP {
public static void main(String[] args) throws IOException {
System.out.println("服务端启动 , 等待连接 .... ");
// 1.创建 ServerSocket对象,绑定端口,开始等待连接
ServerSocket ss = new ServerSocket(6666);
// 2.接收连接 accept 方法, 返回 socket 对象.
Socket server = ss.accept();
// 3.通过socket 获取输入流
InputStream is = server.getInputStream();
// 4.一次性读取数据
// 4.1 创建字节数组
byte[] b = new byte[1024];
// 4.2 据读取到字节数组中.
int len = is.read(b);
// 4.3 解析数组,打印字符串信息
String msg = new String(b, 0, len);
System.out.println(msg);
//5.关闭资源.
is.close();
server.close();
}
}客户端实现:
public class ClientTCP {
public static void main(String[] args) throws Exception {
System.out.println("客户端 发送数据");
// 1.创建 Socket ( ip , port ) , 确定连接到哪里.
Socket client = new Socket("localhost", 6666);
// 2.获取流对象 . 输出流
OutputStream os = client.getOutputStream();
// 3.写出数据.
os.write("你好么? tcp ,我来了".getBytes());
// 4. 关闭资源 .
os.close();
client.close();
}
}2.服务器向客户端回写数据
服务端实现:
public class ServerTCP {
public static void main(String[] args) throws IOException {
System.out.println("服务端启动 , 等待连接 .... ");
// 1.创建 ServerSocket对象,绑定端口,开始等待连接
ServerSocket ss = new ServerSocket(6666);
// 2.接收连接 accept 方法, 返回 socket 对象.
Socket server = ss.accept();
// 3.通过socket 获取输入流
InputStream is = server.getInputStream();
// 4.一次性读取数据
// 4.1 创建字节数组
byte[] b = new byte[1024];
// 4.2 据读取到字节数组中.
int len = is.read(b);
// 4.3 解析数组,打印字符串信息
String msg = new String(b, 0, len);
System.out.println(msg);
// =================回写数据=======================
// 5. 通过 socket 获取输出流
OutputStream out = server.getOutputStream();
// 6. 回写数据
out.write("我很好,谢谢你".getBytes());
// 7.关闭资源.
out.close();
is.close();
server.close();
}
}客户端实现:
public class ClientTCP {
public static void main(String[] args) throws Exception {
System.out.println("客户端 发送数据");
// 1.创建 Socket ( ip , port ) , 确定连接到哪里.
Socket client = new Socket("localhost", 6666);
// 2.通过Scoket,获取输出流对象
OutputStream os = client.getOutputStream();
// 3.写出数据.
os.write("你好么? tcp ,我来了".getBytes());
// ==============解析回写=========================
// 4. 通过Scoket,获取 输入流对象
InputStream in = client.getInputStream();
// 5. 读取数据数据
byte[] b = new byte[100];
int len = in.read(b);
System.out.println(new String(b, 0, len));
// 6. 关闭资源 .
in.close();
os.close();
client.close();
}
}(3)UDP
1. 发送数据
public class SendDemo {
public static void main(String[]args) throws IOException {
//创建发送端的Socket对象(DatagramSocket)
//DatagramSocket()构造数据报套接字并将其绑定到本地主机上的任何可用端口
DatagramSocket ds =new DatagramSocket();
//创建数据,并把数据打包
//DatagramPacket(byte[]buf,intlength,InetAddressaddress,intport)
//构造一个数据包,发送长度为length的数据包到指定主机上的指定端口号。
byte[]bys="hello,udp,我来了".getBytes();
DatagramPacket dp = new DatagramPacket(bys,bys.length,InetAddress.getByName("192.168.1.66"),10086);
//调用DatagramSocket对象的方法发送数据
//voidsend(DatagramPacketp)从此套接字发送数据报包
ds.send(dp);
//关闭发送端
//voidclose()关闭此数据报套接字
ds.close();
}
}2. 接收数据
public class ReceiveDemo {
public static void main(String[]args) throws IOException {
//创建接收端的Socket对象(DatagramSocket)
DatagramSocket ds =new DatagramSocket(12345);
while(true){
//创建一个数据包,用于接收数据
byte[]bys=newbyte[1024];
DatagramPacket dp = new DatagramPacket(bys,bys.length);
//调用DatagramSocket对象的方法接收数据
ds.receive(dp);
//解析数据包,并把数据在控制台显示
System.out.println("数据是:"+newString(dp.getData(),0,dp.getLength()));
}
}
}31. Servlet相关知识
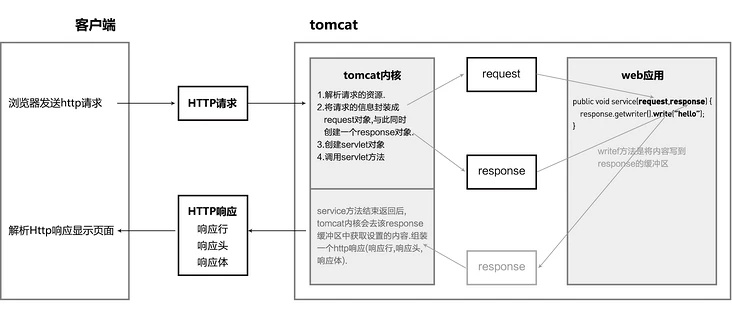
1.浏览器请求流程
2.Tomcat目录介绍
- bin:包含了一些jar , bat文件 。 startup.bat
- conf:tomcat的配置 server.xml web.xml
- lib :tomcat运行所需的jar文件
- logs:运行的日志文件
- temp:临时文件
- webapps:发布到tomcat服务器上的项目,就存放在这个目录。
- work:jsp翻译成class文件存放地
3.配置文件方式创建servlet
1. 创建JavaEE项目
2. 定义一个类,实现Servlet接口
* public class ServletDemo1 implements Servlet
3. 实现接口中的抽象方法
4. 配置Servlet
在web.xml中配置:
<!--配置Servlet -->
<servlet>
<servlet-name>demo1</servlet-name>
<servlet-class>cn.itcast.web.servlet.ServletDemo1</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>demo1</servlet-name>
<url-pattern>/demo1</url-pattern>
</servlet-mapping>
* 执行原理:
1. 当服务器接受到客户端浏览器的请求后,会解析请求URL路径,获取访问的Servlet的资源路径
2. 查找web.xml文件,是否有对应的<url-pattern>标签体内容。
3. 如果有,则在找到对应的<servlet-class>全类名
4. tomcat会将字节码文件加载进内存,并且创建其对象
5. 调用其方法4.注解方式创建servlet
* Servlet3.0 支持注解配置。可以不需要web.xml了。
* 步骤:
1. 创建JavaEE项目,选择Servlet的版本3.0以上,可以不创建web.xml
2. 定义一个类,实现Servlet接口
3. 复写方法
4. 在类上使用@WebServlet注解,进行配置
* @WebServlet("资源路径")
一个Servlet可以定义多个访问路径 : @WebServlet({"/d4","/dd4","/ddd4"})
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface WebServlet {
String name() default "";//相当于<Servlet-name>
String[] value() default {};//代表urlPatterns()属性配置
String[] urlPatterns() default {};//相当于<url-pattern>
int loadOnStartup() default -1;//相当于<load-on-startup>
WebInitParam[] initParams() default {};
boolean asyncSupported() default false;
String smallIcon() default "";
String largeIcon() default "";
String description() default "";
String displayName() default "";
}5.URL和URI的区别
- URL:统一资源定位符 : http://localhost/day14/demo1 中华人民共和国
- URI:统一资源标识符 : /day14/demo1 共和国
6. Http请求头
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, image/gif, image/pjpeg, application/x-ms-xbap, */*
Referer: http://localhost:8080/examples/servlets/servlet/RequestParamExample
Accept-Language: zh-CN
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: localhost:8080
Content-Length: 31
Connection: Keep-Alive
Cache-Control: no-cache
Accept: 客户端向服务器端表示,我能支持什么类型的数据。
Referer : 真正请求的地址路径,全路径
Accept-Language: 支持语言格式
User-Agent: 用户代理 向服务器表明,当前来访的客户端信息。
Content-Type: 提交的数据类型。经过urlencoding编码的form表单的数据
Accept-Encoding: gzip, deflate : 压缩算法 。
Host : 主机地址
Content-Length: 数据长度
Connection : Keep-Alive 保持连接
Cache-Control : 对缓存的操作7.常见的响应头
- Content-Type:text/html;charset=UTF-8 服务器告诉客户端本次响应体数据格式以及编码格式
- Content-disposition:服务器告诉客户端以什么格式打开响应体数据
- 值:
- in-line:默认值,在当前页面内打开
- attachment;filename=xxx:以附件形式打开响应体。文件下载
8.ServletContext对象
ServletContext代表是一个web应用的环境(上下文)对象,(代表整个web应用,可以和程序的容器(服务器)来通信)ServletContext对象 内部封装是该web应用的信息,ServletContext对象一个web应用只有一个
- 问题:一个web应用有几个servlet对象?
- 答: 多个
ServletContext对象的生命周期?
- 创建:该web应用被加载(服务器启动或发布web应用(前提,服务器启动状 态))
- 销毁:web应用被卸载(服务器关闭,移除该web应用)
1. 获取:
1. 通过request对象获取
request.getServletContext();
2. 通过HttpServlet获取
this.getServletContext();
2. 功能:
1. 获取MIME类型:
* MIME类型:在互联网通信过程中定义的一种文件数据类型
* 格式: 大类型/小类型 text/html image/jpeg
* 获取:String getMimeType(String file)
2. 域对象:共享数据
1. setAttribute(String name,Object value)
2. getAttribute(String name)
3. removeAttribute(String name)
* ServletContext对象范围:所有用户所有请求的数据
3. 获取文件的真实(服务器)路径
1. 方法:String getRealPath(String path)
String b = context.getRealPath("/b.txt");//web目录下资源访问
System.out.println(b);
String c = context.getRealPath("/WEB-INF/c.txt");//WEB-INF目录下的资源访问
System.out.println(c);
String a = context.getRealPath("/WEB-INF/classes/a.txt");//src目录下的资源访问
System.out.println(a);9.requestDispatcher与sendRedirect区别
转发过程: 客户端浏览器发送http请求 → web服务器接受此请求 → 调用内部的一个方法在容器内部完成请求处理和转发动作 → 将目标资源发送给客户。
//java代码示例
request.getRequestDispatcher("xxx.jsp或者servlet").forward(request,response);重定向过程: 客户端浏览器发送http请求 → web服务器接收后发送30X状态码响应及对应新的location给客户浏览器 → 客户浏览器发现是30X响应,则自动再发送一个新的http请求,请求url是新的location地址→ 服务器根据此请求寻找资源并发送给客户。
//java代码示例
response.sendRedirect("xxx.jsp或者servlet");转发和重定向对比:
| 转发 | 重定向 | |
|---|---|---|
| 跳转方式 | 服务器端转发 | 客户端转发 |
| 客户端发送请求次数 | 1次 | 2次 |
| 客户端地址栏是否改变 | 不变 | 变 |
| 是否共享request域 | 共享 | 不共享(request域中的数据丢失),必须使用session传递属性 |
| 是否共享response域 | 共享 | 不共享 |
| 范围 | 网站内 | 可以跨站点 |
| JSP | URL不可带参数 | URL可带参数 |
| 是否隐藏路径 | 隐藏 | 不隐藏 |
什么时候使用重定向,什么时候使用转发?
原则上: 要保持request域的数据时使用转发,要访问外站资源的时候用重定向,其余随便;特殊的应用: 对数据进行修改、删除、添加操作的时候,应该用response.sendRedirect()。如果是采用了request.getRequestDispatcher().forward(request,response),那么操作前后的地址栏都不会发生改变,仍然是修改的控制器,如果此时再对当前页面刷新的话,就会重新发送一次请求对数据进行修改,这也就是有的人在刷新一次页面就增加一条数据的原因。
转发与重定向的安全性
转发安全性: 在服务器内部实现跳转,客户端不知道跳转路径,相对来说比较安全。重定向安全性: 客户端参与到跳转流程,给攻击者带来了攻击入口,受威胁的可能性较大。比如一个HTTP参数包含URL,Web应用程序将请求重定向到这个URL,攻击者可以通过修改这个参数,引导用户到恶意站点,并且通过将恶意域名进行十六进制编码,一般用户很难识别这是什么样的URL;或者指引到该网站的管理员界面,如果访问控制没有做好将导致一般用户可以直接进入管理界面。**重定向和转发检查列表:**重定向之前,验证重定向的目标URL。使用白名单验证重定向目标。如果在网站内重定向,可以使用相对路径URL。重定向或者转发之前,要验证用户是否有权限访问目标URL。
32. Cookie&Session
- session与Cookie的区别: 1. session存储数据在服务器端,Cookie在客户端 2. session没有数据大小限制,Cookie有 3. session数据安全,Cookie相对于不安全
- Cookie:数据存储在客户端本地,减少服务器端的存储的压力,安全性不好,客户端 可以清除cookie
@WebServlet("/cookieTest")
public class CookieTest extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) {
//设置Cookie的value
//获取当前时间的字符串,重新设置Cookie的值,重新发送cookie
String str_date = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss").format(new Date());
//URL编码
str_date = URLEncoder.encode(str_date,"utf-8");
System.out.println("编码后:"+str_date);
Cookie cookie = new Cookie("lastTime",str_date);
//设置cookie的存活时间
cookie.setMaxAge(60 * 60 * 24 * 30);//一个月
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
response.addCookie(cookie);
}
}- Session:将数据存储到服务器端,安全性相对好,增加服务器的压力
@WebServlet("/sessionTest")
public class CookieTest extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) {
//1.获得Session对象
HttpSession session = request.getSession();
//2.怎样向session中存取数据(session也是一个域对象)
Session也是存储数据的区域对象,所以session对象也具有如下三个方法:
session.setAttribute(String name,Object obj);
session.getAttribute(String name);
session.removeAttribute(String name);
}
}33. 过滤器,拦截器,监听器的区别
把整个项目的流程比作一条河,那么监听器的作用就是能够听到河流里的所有声音,过滤器就是能够过滤出其中的鱼,而拦截器则是拦截其中的部分鱼,并且作标记。所以当需要监听到项目中的一些信息,并且不需要对流程做更改时,用监听器;当需要过滤掉其中的部分信息,只留一部分时,就用过滤器;**当需要对其流程进行更改,做相关的记录时用拦截器。**监听器更好的应用是用于信息的监听过滤器更好的应用是用于做请求的过滤,拦截无效的请求和信息拦截器则是可以根据实际场景需要,对业务逻辑进行校验和调整。所以类似用户登录校验,拦截器会是更好的选择。
执行顺序:
监听器 > 过滤器 > 拦截器 > servlet执行 > 拦截器 > 过滤器 > 监听器
1.过滤器Filter
过滤器定义在 javax.servlet包,是Servlet规范的一部分,在JavaWeb项目中都可以使用。我们常常使用过滤器来过滤掉一些无效的请求,避免过多无效请求落到servlet、controller上,导致浪费系统的资源。也常用来对请求的编码进行统一的设置,如配置CharacterEncodingFilter作为字符编码过滤器。同时,过滤器Filter是随你的web应用启动而启动的,只初始化一次,以后就可以拦截相关的请求,只有当你的web应用停止或重新部署的时候才能销毁。
过滤器的配置比较简单,直接实现Filter 接口即可,也可以通过@WebFilter注解实现对特定URL拦截,看到Filter 接口中定义了三个方法。
- init() :该方法在容器启动初始化过滤器时被调用,它在 Filter 的整个生命周期只会被调用一次。注意:这个方法必须执行成功,否则过滤器会不起作用。
- doFilter() :容器中的每一次请求都会调用该方法, FilterChain 用来调用下一个过滤器 Filter。
- destroy(): 当容器销毁 过滤器实例时调用该方法,一般在方法中销毁或关闭资源,在过滤器 Filter 的整个生命周期也只会被调用一次
自定义过滤器
执行顺序:如果有两个过滤器:过滤器1和过滤器2
1. 过滤器1
2. 过滤器2
3. 资源执行
4. 过滤器2
5. 过滤器1
1. 定义一个类,实现接口Filter
2. 复写方法
3. 配置拦截路径: `web.xml`或者注解`@WebFilter`
* 过滤器先后顺序问题:
1. 注解配置:按照类名的字符串比较规则比较,值小的先执行,如: AFilter 和 BFilter,AFilter就先执行了。
2. web.xml配置: <filter-mapping>谁定义在上边,谁先执行(1)注解方式:
package com.xiaoming.util;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
@Component
@Order(1)
@WebFilter(urlPatterns = "/user/*",filterName = "filter1")
public class MyFilter1 implements Filter {
// 在Filter初始化的时候调用
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("MyFilter1 has been initialized ...");
}
/** 每个用户请求都会调用到这个方法,校验通过则doFilter放行到下一个过滤器
* 等到请求通过所有过滤链上的校验后,才能到达servlet
* @param servletRequest
* @param servletResponse
* @param filterChain
* @throws IOException
* @throws ServletException
*/
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("doFilter1开始执行,对"+((HttpServletRequest)servletRequest).getRequestURL().toString()+" 进行过滤 ");
System.out.println("检验接口是否被调用,尝试获取contentType如下: " + servletResponse.getContentType());
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("检验接口是否被调用,尝试获取contentType如下: " + servletResponse.getContentType());
System.out.println("doFilter1执行结束");
}
// Filter对象被销毁的时候调用,注意,执行该方法后会在调用一次dofilter
public void destroy() {
System.out.println("MyFilter1 has been destroyed...");
}
}(2)web.xml配置方式:
<filter>
<filter-name>demo1</filter-name>
<filter-class>cn.itcast.web.filter.FilterDemo1</filter-class>
</filter>
<filter-mapping>
<filter-name>demo1</filter-name>
<!-- 拦截路径 -->
<url-pattern>/*</url-pattern>
</filter-mapping>2.拦截器Interceptor
依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上基于Java的反射机制,属于面向切面编程(AOP)的一种运用。由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。但是缺点是只能对controller请求进行拦截,对其他的一些比如直接访问静态资源的请求则没办法进行拦截处理。
拦截器它是链式调用,一个应用中可以同时存在多个拦截器Interceptor, 一个请求也可以触发多个拦截器 ,而每个拦截器的调用会依据它的声明顺序依次执行。
首先编写一个简单的拦截器处理类,请求的拦截是通过HandlerInterceptor 来实现,看到HandlerInterceptor 接口中也定义了三个方法。
- preHandle() :这个方法将在请求处理之前进行调用。注意:如果该方法的返回值为false ,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。
- postHandle():只有在 preHandle() 方法返回值为true 时才会执行。会在Controller 中的方法调用之后,DispatcherServlet 返回渲染视图之前被调用。 有意思的是:postHandle() 方法被调用的顺序跟 preHandle() 是相反的,先声明的拦截器 preHandle() 方法先执行,而postHandle()方法反而会后执行。
- afterCompletion():只有在 preHandle() 方法返回值为true 时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。
package com.xiaoming.util;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MyInterceptor implements HandlerInterceptor {
//对接收到的请求进行前置处理,如果返回true才将请求放行给controller
//如果返回false,执行中断请求
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle has done...");
return true;
}
//执行croller后,渲染视图之前调用
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle has done...");
}
//整个请求结束后执行
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion has done...");
}
}
@Configuration
class InterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new CustomInterceptorA()).addPathPatterns("/**");
registry.addInterceptor(new CustomInterceptorB()).addPathPatterns("/**");
}
}在spring-mvc.xml文件中配置:
<!--配置拦截器-->
<mvc:interceptors>
<mvc:interceptor>
<!--对哪些资源执行拦截操作-->
<mvc:mapping path="/**"/>
<bean class="com.xiaoming.util.MyInterceptor"/>
</mvc:interceptor>
</mvc:interceptors>3. 过滤器和拦截器的区别:
(1)实现原理不同
拦截器是基于java的反射机制的,而过滤器是基于函数回调。
回调函数是一个函数,将会在另一个函数完成执行后立即执行。回调函数是一个作为参数传给另一个Java函数的函数。这个回调函数会在传给的函数内部执行。
- 在我们自定义的过滤器中都会实现一个 doFilter()方法,这个方法有一个FilterChain 参数,而实际上它是一个回调接口。
- ApplicationFilterChain是它的实现类, 这个实现类内部也有一个 doFilter() 方法就是回调方法。
- ApplicationFilterChain里面能拿到我们自定义的xxxFilter类,在其内部回调方法doFilter()里调用各个自定义xxxFilter过滤器,并执行 doFilter() 方法。
- 而每个xxxFilter 会先执行自身的 doFilter() 过滤逻辑,最后在执行结束前会执行filterChain.doFilter(servletRequest, servletResponse),也就是回调ApplicationFilterChain的doFilter() 方法,以此循环执行实现函数回调。
(2)使用范围不同
我们看到过滤器 实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter 的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。
而拦截器(Interceptor) 它是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。不仅能应用在web程序中,也可以用于Application、Swing等程序中。
(3)触发时机不同
过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。

(4)拦截的请求范围不同
项目启动过程中发现,过滤器的init()方法,随着容器的启动进行了初始化。此时浏览器发送请求,发送两个请求,一个是我们自定义的 Controller 请求,另一个是访问静态图标资源的请求。
执行顺序 :
Filter 处理中 -> Interceptor 前置 -> 我是controller -> Interceptor 处理中 -> Interceptor 处理后
Filter 处理中
Interceptor 前置
Interceptor 处理中
Interceptor 后置
Filter 处理中过滤器Filter执行了两次,拦截器Interceptor只执行了一次。这是因为过滤器几乎可以对所有进入容器的请求起作用,而拦截器只会对Controller中请求或访问static目录下的资源请求起作用。
(5)注入Bean情况不同
在实际的业务场景中,应用到过滤器或拦截器,为处理业务逻辑难免会引入一些service服务。
- 过滤器中注入service,发起请求测试一下 ,日志正常打印出“我是方法A”。
- 在拦截器中注入service,发起请求测试一下 ,竟然报错了,debug跟一下发现注入的service是Null
这是因为加载顺序导致的问题,拦截器加载的时间点在springcontext之前,而Bean又是由spring****进行管理。
解决方案也很简单,我们在注册拦截器之前,先将Interceptor 手动进行注入。注意:在registry.addInterceptor()注册的是getMyInterceptor() 实例。
@Configuration
public class MyMvcConfig implements WebMvcConfigurer {
@Bean
public MyInterceptor getMyInterceptor(){
System.out.println("注入了MyInterceptor");
return new MyInterceptor();
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(getMyInterceptor()).addPathPatterns("/**");
}
}(6)控制执行顺序不同
实际开发过程中,会出现多个过滤器或拦截器同时存在的情况,不过,有时我们希望某个过滤器或拦截器能优先执行,就涉及到它们的执行顺序。
过滤器用@Order注解控制执行顺序,通过@Order控制过滤器的级别,值越小级别越高越先执行。
@Order(Ordered.HIGHEST_PRECEDENCE)
@Component
public class MyFilter implements Filter { }拦截器默认的执行顺序,就是它的注册顺序,也可以通过Order手动设置控制,值越小越先执行。
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor2()).addPathPatterns("/**").order(2);
registry.addInterceptor(new MyInterceptor1()).addPathPatterns("/**").order(1);
registry.addInterceptor(new MyInterceptor3()).addPathPatterns("/**").order(3);
}看到输出结果发现,先声明的拦截器 preHandle() 方法先执行,而postHandle()方法反而会后执行。
postHandle() 方法被调用的顺序跟 preHandle() 居然是相反的!如果实际开发中严格要求执行顺序,那就需要特别注意这一点。
Interceptor1 前置
Interceptor2 前置
Interceptor3 前置
我是controller
Interceptor3 处理中
Interceptor2 处理中
Interceptor1 处理中
Interceptor3 后置
Interceptor2 处理后
Interceptor1 处理后4.监听器Listener
web监听器是一种Servlet中的特殊的类,它们能帮助开发者监听web中的特定事件,实现了javax.servlet.ServletContextListener 接口的服务器端程序,它也是随web应用的启动而启动,只初始化一次,随web应用的停止而销毁。主要作用是:感知到包括request(请求域),session(会话域)和applicaiton(应用程序)的初始化和属性的变化。
监听器大概分为以下几种
- ServletContextListener:对Servlet上下文的创建和销毁进行监听
- ServletContextAttributeListener:监听Servlet上下文属性的添加、删除和修改
- HttpSessionListener:对Session的创建和销毁进行监听
- HttpSessionAttributeListener:对Session对象中属性的添加、删除和修改进行监听
- HttpSessionBindingListener:监听Http会话中对象的绑定信息
- HttpSessionActivationListener:监听器监听Http会话的情况
- ServletRequestListener:对请求对象的初始化和销毁进行监听
- ServletRequestAttributeListener:对请求对象属性的添加、删除和修改进行监听
步骤:
1. 定义一个类,实现ServletContextListener接口
2. 复写方法
3. 配置
(1) web.xml
<listener>
<listener-class>cn.itcast.web.listener.ContextLoaderListener</listener-class>
</listener>
* 指定初始化参数<context-param>
(2) 注解:@WebListener34.注解
1. JDK中预定义的一些注解
JDK预设了以下注解,作用于代码:
- @Override - 检查(仅仅是检查,不保留到运行时)该方法是否是重写方法。如果发现其父类,或者是引用的接口中并没有该方法时,会报编译错误。
- @Deprecated - 标记过时方法。如果使用该方法,会报编译警告。
- @SuppressWarnings - 指示编译器去忽略注解中声明的警告(仅仅编译器阶段,不保留到运行时)
- @FunctionalInterface - Java 8 开始支持,标识一个匿名函数或函数式接口。
- @SafeVarargs - Java 7 开始支持,忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告。
2. 自定义注解
元注解:用于描述注解的注解
- @Retention - 标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问。
- @Documented - 标记这些注解是否包含在用户文档中。
- @Target - 标记这个注解应该是哪种 Java 成员。
- @Inherited - 标记这个注解是继承于哪个注解类(默认 注解并没有继承于任何子类)
- @Repeatable - Java 8 开始支持,标识某注解可以在同一个声明上使用多次。
格式:
@元注解
public @interface 注解名称{
属性列表;
}- 本质:注解本质上就是一个接口,该接口默认继承Annotation接口
public interface MyAnno extends java.lang.annotation.Annotation {}
- 属性:接口中的抽象方法要求:
1. 属性的返回值类型有下列取值
基本数据类型、String、 枚举、注解、以上类型的数组
2. 定义了属性,在使用时需要给属性赋值
* 如果定义属性时,使用default关键字给属性默认初始化值,则使用注解时,可以不进行属性的赋值。
* 如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可。
* 数组赋值时,值使用{}包裹。如果数组中只有一个值,则{}可以省略3. 反射获取注解
public static void main(String[] args) throws NoSuchMethodException {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getMethod("test").getAnnotations()) {
System.out.println(annotation.annotationType()); //获取类型
System.out.println(annotation instanceof Test); //直接判断是否为Test
Test test = (Test) annotation;
System.out.println(test.value()); //获取我们在注解中写入的内容
}
}35. 函数式接口
含义:函数式接口在Java中是指:有且仅有一个抽象方法的接口
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda,所以函数式接口就是可以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导。
1. 格式:
修饰符 interface 接口名称 {
public abstract 返回值 类型方法名称 (可选参数信息);//其他非抽象方法内容
}2. @FunctionalInterface
注解与@Override注解的作用类似,Java8中专门为函数式接口引入了一个新的注解:@FunctionalInterface。该注解可用于一个接口的定义上
@FunctionalInterface
public interface MyFunctionalInterface{
void myMethod();
}一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。需要注意的是,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口,使用起来都一样
1. Supplier接口
Supplier接口也被称为生产型接口,如果我们指定了接口的泛型是什么类型,那么接口中的get方法就会生产 什么类型的数据供我们使用。
| 方法名 | 说明 |
|---|---|
| T get() | 按照某种实现逻辑(由Lambda表达式实现)返回一个数据 |
需求:打印出姓名
public class Supplier Demo {
public static void main(String[] args){
String s = getString(()->"林青霞");
System.out.println(s);
Integeri=getInteger(()->30);
System.out.println(i);
}
//定义一个方法,返回一个整数数据
private static Integer getInteger(Supplier<Integer> sup){
returnsup.get();
}
//定义一个方法,返回一个字符串数据
private static String getString(Supplier<String> sup){
returnsup.get();
}
}2. Consumer接口
Consumer接口也被称为消费型接口,它消费的数据的数据类型由泛型指定
| 方法名 | 说明 |
|---|---|
| void accept(T t) | 对给定的参数执行此操作 |
| default Consumer andThen(Consumer after) | 返回一个组合的Consumer,依次执行此操作,然后执行 after操作, |
需求:将两个Consumer接口按照顺序组合到一起使用
public class ConsumerDemo {
public static void main(String[] args) {
//操作一
operatorString("林青霞", s -> System.out.println(s));
//操作二
operatorString("林青霞", s -> System.out.println(
new StringBuilder(s).reverse().toString())
);
System.out.println("--------");
//传入两个操作使用andThen完成
operatorString("林青霞", s -> System.out.println(s), s ->
System.out.println(new StringBuilder(s).reverse().toString()));
}
//定义一个方法,用不同的方式消费同一个字符串数据两次
private static void operatorString(String name, Consumer<String> con1,
Consumer<String> con2) {
// con1.accept(name);
// con2.accept(name);
con1.andThen(con2).accept(name);
}
//定义一个方法,消费一个字符串数据
private static void operatorString(String name, Consumer<String> con) {
con.accept(name);
}
}3. Predicate接口
Predicate接口通常用于判断参数是否满足指定的条件
| 方法名 | 说明 |
|---|---|
| boolean test(T t) | 对给定的参数进行判断(判断逻辑由Lambda表达式实现),返回 一个布尔值 |
| default Predicate negate() | 返回一个逻辑的否定,对应逻辑非 |
| default Predicate and(Predicate other) | 返回一个组合判断,对应短路与 |
| default Predicate or(Predicate other) | 返回一个组合判断,对应短路或 |
需求:返回数组,同时满足如下要求:姓名长度大于2;年龄大于33
public static void main(String[] args) {
String[] strArray = {"林青霞,30", "柳岩,34", "张曼玉,35", "貂蝉,31", "王祖贤, 33"};
List<String> array = myFilter(
strArray, s -> s.split(",")[0].length() > 2,
s -> Integer.parseInt(s.split(",")[1]) > 33
);
for (String str : array) {
System.out.println(str);
}
}
//通过Predicate接口的拼装将符合要求的字符串筛选到集合ArrayList中
private static List<String> myFilter(String[] strArray,
Predicate<String> pre1,
Predicate<String> pre2) {
//定义一个集合
List<String> array = new ArrayList<String>();
//遍历数组
for (String str : strArray) {
if (pre1.and(pre2).test(str)) {
//姓名长度大于2;年龄大于33
array.add(str);
}
}
return array;
}4. Function接口
Function接口通常用于对参数进行处理,转换(处理逻辑由Lambda表达式实现),然后返回一个新的值
| 方法名 | 说明 |
|---|---|
| R apply(T t) | 将此函数应用于给定的参数 |
| default Function andThen(Function after) | 返回一个组合函数,首先将该函数应用于输入,然后将after函 数应用于结果 |
需求:1.将字符串截取得到数字年龄部分; 2.将上一步的年龄字符串转换成为int类型的数据; 3.将上一步的int数据加70,得到一个int结果,在控制台输出。
public static void main(String[] args) {
String s = "林青霞,30";
convert(s, ss -> ss.split(",")[1], Integer::parseInt, i -> i + 70);
}
private static void convert(String str,
Function<String, String> fun1,
Function<String, Integer> fun2,
Function<Integer, Integer> fun3) {
int i = fun1.andThen(fun2).andThen(fun3).apply(str);
System.out.println(i);
}36. Lamda表达式
1. 获取Stream
(1)Collection
- java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
(2)Map
- java.util.Map 接口不是 Collection 的子接口,且其K-V数据结构不符合流元素的单一特征,所以获取对应的流 需要分key、value或entry等情况
(3)数组
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法 of ,使用很简单:Stream.of(array)
2. Stream流中间操作方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
- 延迟方法:返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方 法均为延迟方法。)
- 终结方法:返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调 用。本小节中,终结方法包括 count 和 forEach 方法。
| 方法名 | 说明 |
|---|---|
| Stream filter(Predicate predicate) | 用于对流中的数据进行过滤 |
| Stream limit(long maxSize) | 返回此流中的元素组成的流,截取前指定参数个数的数据 |
| Stream skip(long n) | 跳过指定参数个数的数据,返回由该流的剩余元素组成的 流 |
| static Stream concat(Stream a, Stream b) | 合并a和b两个流为一个流 |
| Stream distinct() | 返回由该流的不同元素(根据Object.equals(Object) )组 成的流 |
| Stream sorted() | 返回由此流的元素组成的流,根据自然顺序排序 |
| Stream sorted(Comparator comparator) | 返回由该流的元素组成的流,根据提供的Comparator进行 排序 |
| Stream map(Function mapper) | 返回由给定函数应用于此流的元素的结果组成的流 |
| IntStream mapToInt(ToIntFunction mapper) | 返回一个IntStream其中包含将给定函数应用于此流的元素 的结果 |
1. filter
可以通过 filter 方法将一个流转换成另一个子集流;
//该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
//如果结果为true,那么Stream流的 filter方法将会留用元素;
//如果结果为false,那么filter方法将会舍弃元素
Stream<T> filter(Predicate<? super T> predicate);
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s ‐> s.startsWith("张"));
}2. map
将流中的元素映射到另一个流中,可以使用 map 方法;
//以将一种T类型转换成为R类型,而这种转换的动作,就称为“映射”
public static void main(String[] args) {
Stream<String> original = Stream.of("10", "12", "18");
Stream<Integer> result = original.map(str‐>Integer.parseInt(str));
}3. limit
limit 方法可以对流进行截取,只取用前n个
//参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作
Stream<T> limit(long maxSize);
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.limit(2);
System.out.println(result.count()); // 2
}4. skip
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
//如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流
Stream<T> skip(long n);
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.skip(2);
System.out.println(result.count()); // 1
}5. concat
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat
//这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
public static void main(String[] args) {
Stream<String> streamA = Stream.of("张无忌");
Stream<String> streamB = Stream.of("张翠山");
Stream<String> result = Stream.concat(streamA, streamB);
}6. sorted
public static void main(String[] args) {
//创建一个集合,存储多个字符串元素
ArrayList<String> list = new ArrayList<String>();
list.add("linqingxia");
list.add("zhangmanyu");
list.add("wangzuxian");
list.add("liuyan");
list.add("zhangmin");
list.add("zhangwuji");
//需求1:按照字母顺序把数据在控制台输出
// list.stream().sorted().forEach(System.out::println);
//需求2:按照字符串长度把数据在控制台输出
list.stream().sorted((s1,s2) -> {
int num = s1.length()-s2.length();
int num2 = num==0?s1.compareTo(s2):num;
return num2;
}).forEach(System.out::println);
}7. map&mapToInt
public static void main(String[] args) {
//创建一个集合,存储多个字符串元素
ArrayList<String> list = new ArrayList<String>();
list.add("10");
list.add("20");
list.add("30");
list.add("40");
list.add("50");
//需求:将集合中的字符串数据转换为整数之后在控制台输出
// list.stream().map(s -> Integer.parseInt(s)).forEach(System.out::println);
// list.stream().map(Integer::parseInt).forEach(System.out::println);
// list.stream().mapToInt(Integer::parseInt).forEach(System.out::println);
//int sum() 返回此流中元素的总和
int result = list.stream().mapToInt(Integer::parseInt).sum();
System.out.println(result);
}3. Stream流终结操作方法
1. forEach:
//该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理
void forEach(Consumer<? super T> action);
public static void main(String[] args) {
Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若");
stream.forEach(name‐> System.out.println(name));
}2. count
//该方法返回一个long值代表元素个数(不再像旧集合那样是int值)
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s ‐> s.startsWith("张"));
System.out.println(result.count()); // 2
}4. Stream流的收集操作
对数据使用Stream流的方式操作完毕后,可以把流中的数据收集到集合中。
常用方法:
| 方法名 | 说明 |
|---|---|
| R collect(Collector collector) | 把结果收集到集合中 |
工具类Collectors提供了具体的收集方式
| 方法名 | 说明 |
|---|---|
| public static Collector toList() | 把元素收集到List集合中 |
| public static Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper,Function valueMapper) | 把元素收集到Map集合 中 |
5. 方法引用
如果我们在Lambda中所指定的操作方案,已经有地方存在相同方案,就没必要再写重复逻辑了
函数式接口是Lambda的基础,而方法引用是Lambda的孪生兄弟
1. 冗余的Lambda场景
(1)例子:
@FunctionalInterface
public interface Printable {
void print(String str);
}其中 printString 方法只管调用 Printable 接口的 print 方法,而并不管 print 方法的具体实现逻辑会将字符串打印到什么地方去。而 main 方法通过Lambda表达式指定了函数式接口 Printable 的具体操作方案为:拿到****String(类型可推导,所以可省略)数据后,在控制台中输出它。
public class Demo01PrintSimple {
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(s ‐> System.out.println(s));
}
}对字符串进行控制台打印输出的操作方案,明明已经有了现成的实现,那就是 System.out 对象中的 println(String) 方法。
(2)改进:
其中的双冒号 :: 写法,这被称为“方法引用”,而双冒号是一种新的语法
public class Demo02PrintRef {
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(System.out::println);
}
}(3)语义分析
上例中, System.out对象中有一个重载的println(String)方法恰好就是我们所需要的。那么对于 printString 方法的函数式接口参数,对比下面两种写法,完全等效:
- Lambda表达式写法: s -> System.out.println(s);
- 方法引用写法: System.out::println
第一种语义是指:拿到参数之后经Lambda之手,继而传递给 System.out.println 方法去处理。
第二种等效写法的语义是指:直接让 System.out 中的 println 方法来取代Lambda。
两种写法的执行效果完全一 样,而第二种方法引用的写法复用了已有方案,更加简洁。
**注:**Lambda 中 传递的参数 一定是方法引用中 的那个方法可以接收的类型,否则会抛出异常
2. 通过对象名引用成员方法
这是最常见的一种用法,与上例相同。如果一个类中已经存在了一个成员方法:
public class MethodRefObject {
public void printUpperCase(String str) {
System.out.println(str.toUpperCase());
}
}函数式接口仍然定义为:
@FunctionalInterface
public interface Printable {
void print(String str);
}那么当需要使用这个printUpperCase 成员方法来替代Printable接口的Lambda的时候,已经具有了 MethodRefObject类的对象实例,则可以通过对象名引用成员方法,代码为:
private static void printString(Printable lambda) {
lambda.print("Hello");
}
public static void main(String[] args) {
MethodRefObject obj = new MethodRefObject();
printString(obj::printUpperCase);
}4. 通过类名称引用静态方法
由于在 java.lang.Math 类中已经存在了静态方法 abs ,所以当我们需要通过Lambda来调用该方法时,有两种写 法。首先是函数式接口:
@FunctionalInterface
public interface Calcable {
int calc(int num);
}第一种写法是使用Lambda表达式:
private static void method(int num, Calcable lambda) {
System.out.println(lambda.calc(num));
}
public static void main(String[] args) {
method(‐10, n ‐> Math.abs(n));
}但是使用方法引用的更好写法是:
private static void method(int num, Calcable lambda) {
System.out.println(lambda.calc(num));
}
public static void main(String[] args) {
method(‐10, Math::abs);
}5. 通过super引用成员方法
如果存在继承关系,当Lambda中需要出现super调用时,也可以使用方法引用进行替代。首先是函数式接口:
@FunctionalInterface
public interface Greetable {
void greet();
}然后是父类 Human 的内容:
public class Human {
public void sayHello() {
System.out.println("Hello!");
}
}最后是子类 Man 的内容,其中使用了Lambda的写法:
public class Man extends Human {
@Override
public void sayHello() {
System.out.println("大家好,我是Man!");
}
//定义方法method,参数传递Greetable接口
public void method(Greetable g){
g.greet();
}
public void show(){
//调用method方法,使用Lambda表达式
method(()‐>{
//创建Human对象,调用sayHello方法
new Human().sayHello();
});
//简化Lambda
method(()‐>new Human().sayHello());
//使用super关键字代替父类对象
method(()‐>super.sayHello());
}
}但是如果使用方法引用来调用父类中的 sayHello 方法会更好,例如另一个子类 Woman :
public class Man extends Human {
@Override
public void sayHello() {
System.out.println("大家好,我是Man!");
}
//定义方法method,参数传递Greetable接口
public void method(Greetable g){
g.greet();
}
public void show(){
method(super::sayHello);
}
}6. 通过this引用成员方法
this代表当前对象,如果需要引用的方法就是当前类中的成员方法,那么可以使用“this::成员方法”的格式来使用方 法引用。首先是简单的函数式接口:
@FunctionalInterface
public interface Richable {
void buy();
}下面是一个丈夫 Husband 类:
public class Husband {
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(() ‐> System.out.println("买套房子"));
}
}开心方法 beHappy 调用了结婚方法marry ,后者的参数为函数式接口 Richable ,所以需要一个Lambda表达式。 但是如果这个Lambda表达式的内容已经在本类当中存在了,则可以对 Husband 丈夫类进行修改:
public class Husband {
private void buyHouse() {
System.out.println("买套房子");
}
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(() ‐> this.buyHouse());
}
}如果希望取消掉Lambda表达式,用方法引用进行替换,则更好的写法为:
public class Husband {
private void buyHouse() {
System.out.println("买套房子");
}
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(this::buyHouse);
}
}7. 类的构造器引用
由于构造器的名称与类名完全一样,并不固定。所以构造器引用使用 类名称::new 的格式表示。首先是一个简单 的 Person 类:
public class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}然后是用来创建 Person 对象的函数式接口:
@FunctionalInterface
public interface PersonBuilder {
Person buildPerson(String name);
}然后是用来创建 Person 对象的函数式接口:
public static void printName(String name, PersonBuilder builder) {
System.out.println(builder.buildPerson(name).getName());
}
public static void main(String[] args) {
printName("赵丽颖", name ‐> new Person(name));
}但是通过构造器引用,有更好的写法:
public static void printName(String name, PersonBuilder builder) {
System.out.println(builder.buildPerson(name).getName());
}
public static void main(String[] args) {
printName("赵丽颖", Person::new);
}8. 数组的构造器引用
数组也是 Object 的子类对象,所以同样具有构造器,只是语法稍有不同。如果对应到Lambda的使用场景中时, 需要一个函数式接口:
@FunctionalInterface
public interface ArrayBuilder {
int[] buildArray(int length);
}在应用该接口的时候,可以通过Lambda表达式:
private static int[] initArray(int length, ArrayBuilder builder) {
return builder.buildArray(length);
}
public static void main(String[] args) {
int[] array = initArray(10, length ‐> new int[length]);
}但是更好的写法是使用数组的构造器引用:
private static int[] initArray(int length, ArrayBuilder builder) {
return builder.buildArray(length);
}
public static void main(String[] args) {
int[] array = initArray(10, int[]::new);
}37.内存泄漏
1. 含义:
内存泄漏:对象已经没有被应用程序使用,但是垃圾回收器没办法移除它们,因为还在被引用着。
在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点:
- 首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;
- 其次,这些对象是无用的,即程序以后不会再使用这些对象。
如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。
而且对于linux kernel,只要不断电就不会释放内存,所以如果内存泄漏积累到一定程度了,就只能重启
2. 回收机制
在Java语言中,判断一个内存空间是否符合垃圾收集的标准有两个:
- 一个是给对象赋予了空值null,再没有调用过;
- 另一个是给对象赋予了新值,这样重新分配了内存空间。
3. 原因
根本原因:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是Java中内存泄漏的发生场景。
具体主要有如下几大类:
(1)静态集合类引起内存泄漏
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
例如:
Static Vector v = new Vector(10);
for (int i = 0; i < 100; i++) {
Object o = new Object();
v.add(o);
o = null;
}在这个例子中,循环申请Object 对象,并将所申请的对象放入一个Vector 中,如果仅仅释放引用本身(o=null),那么Vector 仍然引用该对象,所以这个对象对GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从Vector 中删除,最简单的方法就是将Vector对象设置为null。
(2)监听器
在 java编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如**addXXXListener()**等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
(3)各种连接
比如数据库连接dataSourse.getConnection(),网络连接socket和 io连接,除非其显式的调用了其close() 方法将其连接关闭,否则是不会自动被GC 回收的。 对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。
但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try 里面去的连接,在finally里面释放连接。
(4)内部类和外部模块的引用
内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。此外程序员还要小心外部模块不经意的引用,例如程序员A 负责A 模块,调用了B 模块的一个方法如:public void registerMsg(Object b);这种调用就要非常小心了,传入了一个对象,很可能模块B就保持了对该对象的引用,这时候就需要注意模块B是否提供相应的操作去除引用。
(5)单例模式
不正确使用单例模式是引起内存泄漏的一个常见问题,单例对象在初始化后将在 JVM 的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部的引用,那么这个对象将不能被 JVM 正常回收,导致内存泄漏,如下面的例子:
public class A {
public A() {
B.getInstance().setA(this);
}
...
}
//B类采用单例模式
class B{
private A a;
private static B instance = new B();
public B(){}
public static B getInstance() {
return instance;
}
public void setA(A a) {
this.a = a;
}
public A getA() {
return a;
}
}4. Java 内存分配策略
Java 程序运行时的内存分配策略有三种,分别是静态分配,栈式分配,和堆式分配,对应的,三种存储策略使用的内存空间主要分别是静态存储区(也称方法区)、栈区和堆区。
静态存储区(方法区):主要存放静态数据、全局 static 数据和常量。这块内存在程序编译时就已经分配好,并且在程序整个运行期间都存在。
栈区 :当方法被执行时,方法体内的局部变量(其中包括基础数据类型、对象的引用)都在栈上创建,并在方法执行结束时这些局部变量所持有的内存将会自动被释放。因为栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
堆区 : 又称动态内存分配,通常就是指在程序运行时直接 new 出来的内存,也就是对象的实例。这部分内存在不使用时将会由 Java 垃圾回收器来负责回收。
- 局部变量 的基本数据类型和引用存储于栈中,引用的对象实体存储于堆中。—— 因为它们属于方法中的变量,生命周期随方法而结束。
- 成员变量 全部存储于堆中(包括基本数据类型,引用和引用的对象实体)—— 因为它们属于类,类对象终究是要被new出来使用的。
38. SpringBoot读取Resource目录下的资源文件
1. 使用ResourceUtils获取
导包:import org.springframework.util.ResourceUtils;
1.1 获取文件绝对路径
- 先获取绝对路径地址,然后通过地址生成File文件
String path = ResourceUtils.getURL(ResourceUtils.CLASSPATH_URL_PREFIX+"logback.xml").getPath();
System.out.println("文件绝对路径="+path); // D:/ideaProject/treasure-chest/wshoto/target/classes/logback.xml
FileInputStream inputStream1 = new FileInputStream(path);1.2 直接获取文件
- 1.1的简略版本,省去了获取绝对路径
File file = ResourceUtils.getFile(ResourceUtils.CLASSPATH_URL_PREFIX+"logback.xml");
2. 类加载器获取
2.1 类加载器种类
- **引导类加载器(Bootstrap CLassLoader)**它是由本地代码(c/c++)实现的,你根本拿不到他的引用,但是他实际存在,并且加载一些重要的类,它加载(%JAVA_HOME%\jre\lib),如rt.jar(runtime)、i18n.jar等,这些是Java的核心类。 他是用原生代码来实现的,并不继承自 java.lang.ClassLoader。
- **扩展类加载器(Extension CLassLoader)**虽说能拿到,但是我们在实践中很少用到它,它主要加载扩展目录下的jar包, %JAVA_HOME%\lib\ext
- **系统类加载器(System CLassLoader)**它主要加载我们应用程序中的类,如Test,或者用到的第三方包,如jdbc驱动包等。这里的父类加载器与类中继承概念要区分,它们在class定义上是没有父子关系的。
2.2 获取类加载器:
- 获取加载当前类的类加载器,可能是"启动类加载器"、“拓展类加载器”、"系统类加载器"等,取决于当前类是由哪个加载器加载的;
//获取当前类的加载器
ClassLoader classLoader = Test.class.getClassLoader();- 获取当前线程上下文的类加载器,用户可以自己设置,java se环境下一般是AppClassLoader、java ee环境下一般是WebappClassLoader
//获取当前线程上下文类加载器
ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader();- 获取系统类加载器 System CLassLoader
//获取系统类加载器 System CLassLoader
ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader();- 获取当前线程的ClassLoader
ClassLoader contextClassLoader1 = Thread.currentThread().getContextClassLoader();
2.3 通过类加载器获取资源
ClassLoader loader = ClassLoader.getSystemClassLoader();
InputStream inputStream2 = loader.getResourceAsStream("logback.xml");3. ClassPathResource获取文件(推荐)
- 读取classPaths路径下的文件
Resource resource = new ClassPathResource("logback.xml");
File file = resource2.getFile();